

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- jquery
- Board
- SpringBoot
- git
- mysql
- Oracle
- html
- API
- Eclipse
- 이클립스
- 배열
- 문자열
- Uipath
- db
- Controller
- Scanner
- jsp
- string
- View
- MVC
- Array
- 조건문
- Database
- React
- 상속
- spring
- JDBC
- Thymeleaf
- rpa
- Java
- Today
- Total
유정잉
17일차 MySQL [ 이론 ] ( select..from, join ) 본문
[ SELECT... FROM 이론 ]
- 원하는 데이터를 가져와 주는 기본적인 구문, 가장 많이 사용되는 구문이다.
- 데이터베이스 내 테이블에서 원하는 정보 추출하는 기능

※ SELECT와 FROM
▷ SELECT * : 선택된 DB가 employees 라면 다음 두 쿼리는 동일
select * from employees.titles;
select * from titles;
▷ SELECT 열 이름 : 테이블에서 필요로 하는 열만 가져오기 가능 하다.
- 여러 개의 열을 가져오고 싶을 때는 콤마 ' , '로 구분한다.
- 열 이름의 순서는 출력하고 싶은 순서대로 배열 가능하다.
※ 특정 조건의 데이터만 조회
▷ 기본적인 WHERE절 : 조회하는 결과에 특정한 조건 줘서 원하는 데이터만 보고 싶을 때 사용한다. SELECT 필드이름 FROM 테이블이름 WHERE 조건식; 조건이 없을 경우 테이블의 크기가 클수록 찾는 시간과 노력이 증가한다. 관계 연산자의 사용 : ‘…했거나’, ‘… 또는’ - OR 연산자 • ‘...하고’, ‘…면서’, ‘… 그리고’ - AND 연산자이다. 조건 연산자는(=, <, >, <=, >=, < >, != 등)와 관계 연산자(NOT, AND, OR 등)의 조합으로 알맞은 데이터를 효율적으로 추출한다.
▷ BETWEEN… AND와 IN( ) 그리고 LIKE : 데이터가 숫자로 구성되어 있어 연속적인 값 – BETWEEN… AND 사용 가능하다. 이산적인 (Discrete) 값의 조건 – IN( ) – Ex) SELECT Name, addr FROM userTbl WHERE addr= ' 경남' OR addr= '전남' OR addr= '경북'; » SELECT Name, addr FROM userTbl WHERE addr IN ('경남','전남','경북'); 이다. 문자열의 내용 검색하기 위해 LIKE 연산자 사용 – 문자 뒤에 % - 무엇이든(%) 허용 – 한 글자와 매치하기 위해서는 ‘_’사용한다.
※ ANY/ALL/SOME ,서브쿼리(SubQuery, 하위쿼리)
▷ 서브쿼리 : 쿼리문 안에 또 쿼리문이 들어 있는 것이다. 서브쿼리 사용하는 쿼리로 변환 예제 – 김경호보다 키가 크거나 같은 사람의 이름과 키 출력 => WHERE 조건에 김경호의 키를 직접 써줘야 한다.
[ SELECT Name, height FROM userTBL WHERE height > 177; – SELECT Name, height FROM userTbl WHERE height > (SELECT height FROM userTbl WHERE Name = '김경호'); ] => 서브쿼리의 결과가 둘 이상이 되면 에러 발생
▷ ANY 구문의 필요성 : ANY는 서브쿼리의 여러 개의 결과 중 한 가지만 만족해도 가능하고, SOME은 ANY와 동일한 의미로 사용 – = ANY 구문은 IN과 동일한 의미이다. ALL은 서브쿼리의 여러 개의 결과를 모두 만족시켜야 한다.
※ 원하는 순서대로 정렬하여 출력 : ORDER BY
▷ ORDER BY절 : 결과물에 대해 영향을 미치지는 않는다. 결과가 출력되는 순서를 조절하는 구문이다. 기본적으로 오름차순 (ASCENDING) 정렬한다. 내림차순 (DESCENDING) 으로 정렬할 경우 열 이름 뒤에 DESC 적어주어야 한다. ORDER BY 구문을 혼합해 사용하는 구문도 가능하다 ( – SELECT Name, height FROM userTbl ORDER BY height DESC, name ASC; – 키가 큰 순서로 정렬하되 만약 키가 같을 경우 이름 순으로 정렬 – ASC(오름차순)는 디폴트 값이므로 생략 )
▷ 중복된 것은 하나만 남기는 DISTINCT : 중복된 것을 골라서 세기 어려울 때 사용하는 구문이다. 테이블의 크기가 클수록 효율적이다. 중복된 것은 1개씩만 보여주면서 출력한다.
▷ 출력하는 개수를 제한하는 LIMIT : 일부를 보기 위해 여러 건의 데이터를 출력하는 부담 줄인다. 상위의 N개만 출력하는 ‘LIMIT N’ 구문 사용한다. 서버의 처리량을 많이 사용해 서버의 전반적인 성능을 나쁘게 하는 악성 쿼리문 개선할 때 사용한다.
▷ 테이블을 복사하는 CREATE TABLE … SELECT : 테이블을 복사해서 사용할 경우 주로 사용한다. CREATE TABLE 새로운테이블 (SELECT 복사할열 FROM 기존테이 블). 지정된 일부 열만 테이블로 복사하는 것도 가능하다. PK나 FK 같은 제약 조건은 복사되지 않음 – Workbench의 [Navigator]에서 확인 가능하다.

※ GROUP BY 및 HAVING 그리고 집계 함수
▷ GROUP BY절 : 말 그대로 그룹으로 묶어주는 역할이다. 집계 함수 (Aggregate Function) 함께 사용하면 효율적인 데이터 그룹화 (Grouping) – Ex) 각 사용자 별로 구매한 개수를 합쳐 출력한다. 읽기 좋게 하기 위해 별칭 (Alias) 사용한다.

▷ GROUP BY와 함께 자주 사용되는 집계 함수 (집합 함수)

▷ Having절 : WHERE와 비슷한 개념으로 조건 제한한다. 집계 함수에 대해서 조건 제한하는 편리한 개념이다. HAVING절은 꼭 GROUP BY절 다음에 나와야 한다.
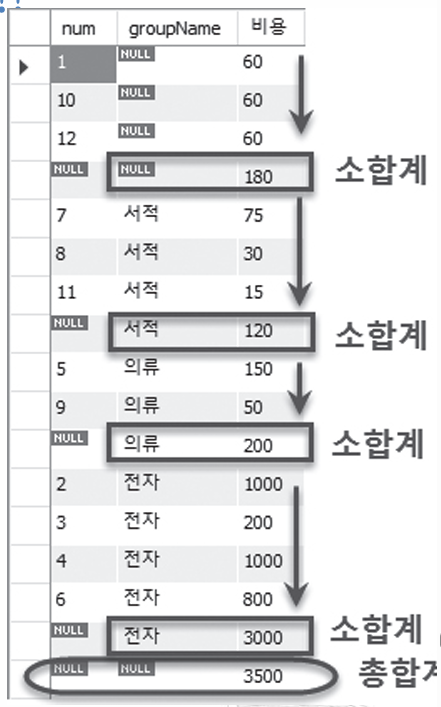
▷ ROLLUP : 총합 또는 중간합계가 필요할 경우 사용한다. GROUP BY절과 함께 WITH ROLLUP문 사용한다. Ex) 분류(groupName) 별로 합계 및 그 총합 구하기
※ SQL의 분류
▷ DML (Data Manipulation Language) : 데이터 조작 언어 / 데이터를 조작(선택, 삽입, 수정, 삭제)하는 데 사용되는 언어 / DML 구문이 사용되는 대상은 테이블의 행 / DML 사용하기 위해서는 꼭 그 이전에 테이블이 정의되어 있어야 함 / SQL문 중 SELECT, INSERT, UPDATE, DELETE가 이 구문에 해당 / 트랜잭션 (Transaction)이 발생하는 SQL도 이 DML에 속함 – 테이블의 데이터를 변경(입력/수정/삭제)할 때 실제 테이블에 완전 히 적용하지 않고, 임시로 적용시키는 것 – 취소 가능!
▷ DDL (Data Definition Language) : 데이터 정의 언어 / 데이터베이스, 테이블, 뷰, 인덱스 등의 데이터베이스 개체를 생성/ 삭제/변경하는 역할 / CREATE, DROP, ALTER 구문 / DDL은 트랜잭션 발생시키지 않음 – 되돌림(ROLLBACK)이나 완전적용(COMMIT) 사용 불가 – DDL문은 실행 즉시 MySQL에 적용
▷ DCL (Data Control Language) : 데이터 제어 언어 / 사용자에게 어떤 권한을 부여하거나 빼앗을 때 주로 사용하는 구문 / GRANT/REVOKE/DENY 구문
※ 테이블의 삽입 INSERT
▷ INSERT문의 기본 : 테이블 이름 다음에 나오는 열 생략 가능 – 생략할 경우에 VALUE 다음에 나오는 값들의 순서 및 개수가 테이 블이 정의된 열 순서 및 개수와 동일해야 함
▷ 자동으로 증가하는 AUTO_INCREMENT : INSERT에서는 해당 열이 없다고 생각하고 입력 – INSERT문에서 NULL 값 지정하면 자동으로 값 입력 / 1부터 증가하는 값 자동 입력 / 적용할 열이 PRIMARY KEY 또는 UNIQUE 일 때만 사용가능 / 데이터 형은 숫자 형식만 사용 가능
▷ 데이터의 삽입 : INSERT
▷ 대량의 샘플 데이터 생성 : INSERT INTO… SELECT 구문 사용 / 다른 테이블의 데이터를 가져와 대량으로 입력하는 효과 / SELECT문의 열의 개수 = INSERT 할 테이블의 열의 개수
형식 : INSERT INTO 테이블이름 (열이름1, 열이름2, ...) SELECT문 ;
▷ 데이터의 수정 : UPDATE
▷ 데이터의 삭제 : DELETE FROM : 행 단위로 데이터 삭제하는 구문
▷ DELETE FROM 테이블이름 WHERE 조건;
▷ 테이블을 삭제하는 경우의 속도 비교 : DML문인 DELETE는 트랜잭션 로그 기록 작업 때문에 삭제 느림 / DDL문인 DROP과 TRUNCATE문은 트랜잭션 없어 빠름
▷ 조건부 데이터 입력, 변경 기본 키가 중복된 데이터를 입력 한 경우 : 오류로 입력 불가 대용량 데이터 처리의 경우 에러 발생하지 않은 구문 실행 / INSERT IGNORE문 사용 - 에러 발생해도 다음 구문으로 넘어가게 처리 / 에러 메시지 보면 적용되지 않은 구문이 어느 것인지 구분 가능 / 기본 키가 중복되면 데이터를 수정되도록 하는 구문도 활용 가능 – ON DUPLICATE KEY UPDATE 구문 사용 가능
[ 조인 JOIN 이론 ]
※ 조인 (Join) : 두 개 이상의 테이블을 서로 묶어서 하나의 결과 집합으로 만들어 내는 작업
※ 데이터베이스의 테이블 :
→ 여러 개의 테이블로 분리하여 저장 – 중복과 공간 낭비를 피하고 데이터의 무결성 위함
→ 분리된 테이블들은 서로 관계(Relation) 를 가짐 – 1대 다 관계에서 일어나는 데이터 처리 필요성
※ INNER JOIN(내부 조인) : 조인 중에서 가장 많이 사용되는 조인이다. 대개의 업무에서 조인은 INNER JOIN 사용한다. 일반적으로 JOIN이라고 얘기하는 것이 이 INNER JOIN 지칭한다.

※ OUTER JOIN(외부 조인) : 조인의 조건에 만족되지 않는 행까지도 포함시키는 것이다. ‘왼쪽 테이블의 것은 모두 출력되어야 한다’ 고 해석하면 이해 하기 쉽다.

※ SELF JOIN(자체 조인) : 자기 자신과 자기 자신이 조인한다는 의미이다.
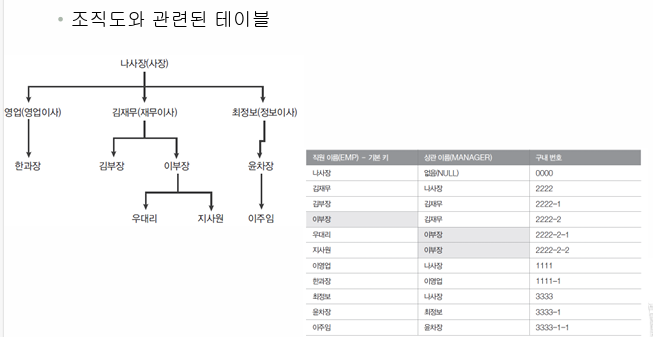
※ UNION / UNION ALL / NOT IN / IN : 두 쿼리의 결과를 행으로 합치는 것

[ MySQL에서 지원하는 데이터 형식의 종류 ]
※ 숫자 데이터 형식

※ 문자 데이터 형식

※ 날짜와 시간 데이터 형식

[ 변수의 사용 ]
- Workbench를 재시작할 때까지는 계속 유지
- Workbench를 닫았다가 재시작하면 소멸
- 변수의 선언과 값의 대입 형식
[ MySQL 내장 함수 ]
※ 제어 흐름 함수 : 제어 흐름 함수는 프로그램의 흐름 제어하는 역할이다.
IF (수식, 참, 거짓) – 수식이 참 또는 거짓인지 결과에 따라서 2중 분기
IFNULL(수식1, 수식2) – 수식1이 NULL이 아니면 수식1이 반환, 수식1이 NULL이면 수식2가 반환
※ 문자열 함수 :
UCASE(문자열), LCASE(문자열) – 소문자를 대문자로, 대문자를 소문자로 변경
UPPER(문자열), LOWER(문자열) – 소문자를 대문자로, 대문자를 소문자로 변경
LPAD(문자열, 길이, 채울문자열), RPAD(문자열, 길이, 채울문자열) – 문자열을 길이만큼 늘린후에 빈곳을 채울 문자열로 채움
LTRIM(문자열), RTRIM(문자열) – 문자열의 왼쪽/오른쪽 공백을 제거 – 중간의 공백은 제거되지 않음
TRIM(문자열), TRIM(방향 자를_문자열 FROM 문자열) – TRIM(문자열)은 문자열의 앞뒤 공백을 모두 없앰 – TRIM(방향 자를_문자열 FROM 문자열) 에서 방향은 LEADING( 앞), BOTH(양쪽), TRAILING(뒤) 으로 표시
REPEAT(문자열, 횟수) – 문자열을 횟수만큼 반복
REPLACE(문자열, 원래 문자열, 바꿀 문자열) – 문자열에서 원래 문자열을 찾아서 바꿀 문자열로 바꿈
REVERSE(문자열) – 문자열의 순서를 거꾸로 바꿈
SPACE(길이) – 길이만큼의 공백을 반환
SUBSTRING(문자열, 시작위치, 길이) 또는 SUBSTRING(문자열 FROM 시작위치 FOR 길이) – 시작위치부터 길이만큼 문자를 반환 – 길이가 생략되면 문자열의 끝까지 반환
SUBSTRING_INDEX(문자열, 구분자, 횟수) – 문자열에서 구분자가 왼쪽부터 횟수 번째까지 나오면 그 이후의 오 른쪽은 버림 – 횟수가 음수면 오른쪽부터 세고 왼쪽을 버림
※ 수학 함수 :
ABS(숫자) – 숫자의 절댓값 계산
ACOS(숫자), ASIN(숫자), ATAN(숫자), ATAN2(숫자1, 숫자2), SIN( 숫자), COS(숫자), TAN(숫자) – 삼각 함수와 관련된 함수 제공
CEILING(숫자), FLOOR(숫자), ROUND(숫자) – 올림, 내림, 반올림 계산
CONV(숫자, 원래 진수, 변환할 진수) – 숫자를 원래 진수에서 변환할 진수로 계산
RAND( ) – RAND( )는 0 이상 1 미만의 실수 구함 – ‘m<= 임의의 정수 < n’를 구하고 싶다면 FLOOR(m + (RAND( ) * (n-m) ) 사용
SIGN(숫자) – 숫자가 양수, 0, 음수인지 판별 – 결과는 1, 0, -1 셋 중에 하나 반환
TRUNCATE(숫자, 정수) – 숫자를 소수점을 기준으로 정수 위치까지 구하고 나머지는 버림 12/17
※ 날짜 및 시간 함수 :
ADDDATE(날짜, 차이), SUBDATE(날짜, 차이) – 날짜를 기준으로 차이를 더하거나 뺀 날짜 구함
ADDTIME(날짜/시간, 시간), SUBTIME(날짜/시간, 시간) – 날짜/시간을 기준으로 시간을 더하거나 뺀 결과를 구함
CURDATE( ), CURTIME( ), NOW( ), SYSDATE( ) – CURDATE( )는 현재 연-월-일 – CURTIME( )은 현재 시:분:초 – NOW( )와 SYSDATE( )는 현재 ‘연-월-일 시:분:초
[ Query창 글씨 크기 키우는 법 ]
Edit -> Preference -> Fonts & Colors -> SQL Editor -> 숫자 바꾸기 -> Ok


[ MySQL 오류 ]
SQL syntax 는 문법오류 Error Code 1050은 이미 Table이 존재한다는 오류
[ MySQL api ]
MySQL :: MySQL 8.0 Reference Manual :: 14.7 Date and Time Functions
MySQL :: MySQL 8.0 Reference Manual :: 14.7 Date and Time Functions
14.7 Date and Time Functions This section describes the functions that can be used to manipulate temporal values. See Section 13.2, “Date and Time Data Types”, for a description of the range of values each date and time type has and the valid formats
dev.mysql.com
[ Create Schemas ]
Administration과 Schemas중 Schemas 선택 -> Navigator창에 오른쪽 버튼 클릭 -> Create Schemas -> 이름 설정
[ create table ]
- 기본키, 외래키, 후보키
※ 기본키 : 식별할 수 있는 값 not nul, 중복불가능 !! (학생아이디,과목코드,...)
※ 외래키 : 외래키 = 참조키 즉, 수강테이블에서 .. 할때 필요한
※ 후보키 : 후보키 = 대체키 즉, 기본키를 대체할만 한 키 (보통 개발자가 인위적으로 증가시킴)
왼쪽 위에 Create a new SQL tab for executing queries 클릭 -> SQL File 숫자 클릭 -> 쿼리창에 create table 테이블명


- ;이 끝나는 지점이 에서 실행하면 한 블록씩 실행됨. 주황색블록 한번 실행되고 핑크색 실행 됨.
- 그래서 전체 드래그 Ctrl+A 후 Ctrl + Enter or 번개모양 클릭 하면 전체 실행 됨.
- Ctrl+Shift+Enter 드래그 없이 전체 실행
( 전체 드래그 아니면 한줄 한줄 해야하기 때문에 10 12 20 22 각 줄을 클릭하고 Ctrl+Enter해야지 실행됨 )
- stu_no char(9), -> 학번은 최대 (9)개 올수 있다.
- stu_name varchar(12), -> 가변길이
- stu_height decimal(5,2), -> 정수 5개 소수 2 개
- constraint 제약조건 primary key(stu_no)가 우리를 구별짓는 식별자
- desc student; 테이블 구조 확인하고 싶을 때 쓰는 명령어 ( 주황네모 보라네모 잘 만들어졌는지 확인하는 작업 )
- 이 테이블에서 엔티티는 Student / 속성은 필드 이름 stu_no stu_name stu_dept...
[ insert into 테이블명 values( ); ]
- 위에서 만들어논 테이블 ( enrol, student, subject ) 에 값 추가하기
- insert into student values(20153075,'옥한빛','기계',1,'C','M',177,80);


insert into student values, insert into enrol values, insert into subject values를 통해 만들어진 테이블에 값 추가함 !!
그리고 확인하고 싶은 테이블에 [ 오른쪽버튼 -> Select Rows - Limit 1000 클릭 ] -> 핑크색네모를 보면 테이블에 값 추가 된거 알 수 있음
[ use 데이터베이스이름 ]
하기 전에 반드시 use yujung;을 적어야지 아니면 원하지 않는 데이터베이스에 쿼리가 들어갈 수도 있음 !!!
이 데이터베이스에서 쿼리문 짜겠단 의미 !
USE 구문 : SELECT문 학습 위해 사용할 데이터베이스 지정 -> 지정해 놓은 후 특별히 다시 USE문 사용하거나 다른 DB 를 사용하겠다고 명시하지 않는 이상 모든 SQL문은 지정 DB에서 수행됨
Workbench 에서 직접 선택해서 사용도 가능 : [Navigator]의 [Schemas] 탭 – employees 데이터베이스를 더블 클릭하면 진한 글자 전환 – 왼쪽 아래‘Active schema changed to employees’

[ SELECT... FROM ]
- select *from 테이블명; : 모든 데이터 추출
- select stu_no, stu_name from 테이블명; : 원하는 데이터만 추출

[ enr_grade+10 grade에 점수 +10을 추가하는 연산작업도 가능 !! ]

[ 두가지 속성을 더해서 추출 하는 contact함수 ]
- select concat(stu_dept,stu_name) from student;
- stu_name as 학생이름을 통해 이름을 지어줄 수도 있음 !!

[ 중복된 데이터를 제거하고 출력하는 distinct 함수 ]
- select distinct stu_dept from student;

[ limit 원하는 만큼만 데이터 가져오기 ]
- select * from student limit 5;
-- 5개 절만 가져오기
- select * from student limit 1,5;
-- 인덱스 1부터 5개절 가져오기

[ where절 사용 ]
- 컴퓨터정보 학생들을 검색하기 , and를 사용하여 두가지 조건 모두를 충족시키는 정보를 검색할 수도 있다.
- select * from student where stu_dept = '컴퓨터정보';
-- student로 부터 모든 정보에서 학과명에 컴퓨터정보있는 정보 가져오기
- select * from student where stu_dept='컴퓨터정보' and stu_grade=2;
-- and를 사용해서 컴퓨터정보학과와 2학년 정보 둘다 조건을 충족하는 정보만 가져오기

[ 범위조건 where between ]
- % : 0개 이상 문자
- _ : 1개의 문자
- between 60 and 70 : 60과 70사이
- not , not in, <> ('컴퓨터정보', '기계') : 컴퓨터정보나 기계가 있으면 출력 or이랑 같은 뜻
where not stu_dept = '컴퓨터정보' : 컴퓨터정보만 빼고 출력 이외라는 뜻 세가지 방법 !
where stu_dept not in(컴퓨터정보);
where stu_dept <>('컴퓨터정보');

[ null 값 존재 여부 확인 ]
- select * from student where stu_height is null;
-- 키값이 비어있는 조건을 찾는 작업
- select * from student where stu_height is not null;
-- 키값이 비어있는 조건을 빼고 찾는 작업

[ ifnull / nullif ]
- ifnull(수식1, 수식2) : 수식 1이 null이 아니면 수식 1 반환, null이면 수식 2 반환
select ifnull(stu_height,0) from student;
-- null값만 0 출력 나머진 원래 키 출력
- nullif(인수1, 인수2) : 두개값 비교해서 값 같으면 null반환, 아니면 인수1 반환
select ifnull(nullif('A','A'),'널값');
-- 널값 출력 ifnull(null,'널값');

[ 순서화 정렬작업 ]
- select stu_no, stu_name from student order by stu_no;
-- 학번 이름 순으로 정렬 오름차순(작->큰)
- select stu_no, stu_name from student order by stu_no desc;
-- 내림차순 (큰->작)

[ order by ]
- 별칭이 붙어있는 열을 기준으로 정렬, 열의 순서번호 이용하여 정렬
- select stu_no, stu_name, stu_dept, stu_weight-5 as target from student order by target;
-- 별칭이 붙어있는 열을 기준으로 정렬
- select stu_no, stu_name, stu_dept, stu_weight-5 as target from student order by 3;
-- 3번째 열을 기준 ( stu_dept기준으로 정렬 됨 )
- select stu_no, stu_name, stu_dept, stu_weight-5 as target from student order by stu_weight-5;
-- 몸무게에서 -5한 값을 기준으로 정렬하겠다
- select stu_no, stu_name, stu_dept, stu_weight-5 as target from student order by stu_dept, target;
-- 학과가 먼저 정렬되고 그 이후 target 정렬됨
- select stu_no, stu_name, stu_dept, stu_weight-5 as target from student order by stu_dept desc, target desc;
-- 둘다내림차순 하려면 둘다 desc 적어줘야함 만약 하나만 적어주면 적어준 곳만 내림차순 안 적은곳은 오름차순

[ 사칙연산 ]
▷ 사칙연산
select 1+2; -- 3출력
select 3*(2+4)/2, 'hi';
select 10%3;
▷ 문자열에 사칙연산을 가하면 0으로 인식
select 'AB' + 3; -- 3출력
select 'AB' * 3; -- 0출력
▷ true는 1, false는 0
select true, false;
-- true는 1 출력 false는 0 출력
select true is true;
-- true니깐 1출력
select 2+4=6 or 2*4=8;
-- or니깐 둘중 하나만 맞아도 참. 즉, true 1 출력
select 'B'='b';
-- MySQL의 기본 사칙 연산자는 대소문자 구분하지 않는다. 즉, true 1 출력
select 10 between 15 and 20;
-- flase 0 출력
select 'apple' not between 'banana' and 'computer';
-- ture 1 출력
select 1+2 in(2,3,4);
-- true 1 출
select 'hi' in (1,true,'hi');
-- hi가 in안에 들어있냐 -> true 1 출력
▷ round (반올림)
select round(345.678),round(345.678,0),round(345.678,1),round(345.678,2),
round(345.678,-1); -- 346, 346, 345.7, 345.68, 350 출력
▷ truncate(버림,소숫점자리)
select truncate(1234.56789, 1), truncate(1234.56789, 2), truncate(1234.56789, -1); -- 1234.5, 1234.56, 1230 출력
select truncate(1234.56789, -2), truncate(1234.56789, -3); -- 1200, 1000 출력
▷ upper (대문자), lower (소문자)
select upper('korea');
select lower('KOREA');
▷ abs(절대값), pow(제곱), power(제곱), sqrt(루트), concat(값 연결)
select abs(1), abs(-1), abs(3-10);
select pow(2,3), power(5,2), sqrt(16);
select concat('hello',' ','2024','03','13');
▷ concat_ws (괄호안에 내용이 첫번째 매개변수로 이어 붙여짐) -- 자주 사용
select concat_ws('-','2024',3,13,'PM');
-- 2024-3-13-PM으로 출력
▷ substr ( 원하는 위치 문자열 출력 )
select substr('ABCDEFGH', 3),substr('ABCDEFGH',3,2),substr('ABCDEFGH', -4),substr('ABCDEFGH', -4,2);
-- 3번째부터 끝까지 CDEFGHC, 3번째 C부터 글자 2개 CD, 뒤에서부터 4글자 EFGH, 뒤에서4번째 E부터 2개 EF
▷ length ( 문자열의 바이트 길이), char_length(문자열의 문자길이)
select length('ABCDEFGH'),
-- 문자열의 바이트 길이 / 영어바이트는1임. 8출력
char_length('ABC');
-- 문자열의 문자길이 3 출력
select length('안녕하세요'), char_length('안녕하세요');
-- 한글바이트 15 출력, char 문자열의 길이 5출력
select char_length('안녕하세요'),character_length('안녕하세요');
-- 위랑 똑같은 결과 똑같은 말임
▷ trim (양쪽공백 제거), rtrim (오른쪽 공백제거), ltrim(왼쪽 공백제거)
select concat('|', ltrim(' hello'), '|'), -- left trim 왼쪽공백제거
-- |hello| 출력
concat('|', rtrim(' hello '), '|'), -- right trim 오른쪽공백제거
-- |hello| 출력
concat('|', trim(' hello '), '|'); -- trim 양쪽공백제거
-- |hello| 출력 / 공백 길이는 상관 없이 전부 제거
▷ lpad(S, N, P) S가 N이 될 때 까지 P를 왼쪽에 이어 붙이는 작업
select lpad('ABC',5,'#'); -- ##ABC 출력
▷ rpad(S, N, P) S가 N이 될 때 까지 P를 오른쪽에 이어 붙이는 작업
select rpad('ABC',5,'@'); -- ABC@@ 출력
▷ replace (내용,old,new) 내용에 old가 new로 바뀜
select replace ('버거킹에서 버거킹 햄버거 먹었다','버거킹','맘스터치');
-- 맘스터치에서 맘스터치 햄버거 먹었다 출력
▷ instr(S,s) S중 s의 첫 위치 반환하는 함수
select instr('ABCDE','ABC'), instr('ABCDE','BC'), instr('ABCDE','C');
-- ABCDE중에서 ABC의 첫위치 1 출력 / ABCDE중 BC의 첫위치2 출력 / ABCDE 중 C의 첫위치 3 출력
▷ cast(A as T) : A를 T 자료형으로 변환 즉, 형변환 함수
select '01' = '1', -- false 0 출력
cast('01' as decimal) = cast('1' as decimal);
-- cast 형변환 ! '01' 문자를 as decimal로 true 1 출력
▷ date_format 날짜형식 (포팅)
select empno, ename, cast(hiredate as char), date_format(hiredate, '%Y-%m') as 입사년월 from emp;
▷ format(숫자, 소수점 자리수)
select stu_dept, format(avg(stu_height),0) from student group by stu_dept;
-- 몸무게 소숫점 지우기
▷ convert(A,T) : A를 T 자료형으로 변환
select '01' = '1', -- false 0 출력
convert('01', decimal) = convert('1', decimal);
-- cast보다 conver가 더 많이 사용 됨 true 1 출력
▷ 날짜함수
select date(now()); -- 연월일
select time(now()); -- 시분초
select timestamp(now()); -- 현재 연월일 시분초
select sysdate(); -- 현재 연월일 시분초
select curdate(); -- 연월일
▷ adddate(date, interval expr) (adddate와 date_add는 똑같음 그치만 adddate로 주요 사용 date_add보단)
select adddate(now(), interval 1 day);
-- 오늘 기준으로 다음날 출력 (24시간 후)
select adddate(now(), interval 1 month);
-- 오늘 기준으로 다음달 출력 (한달 후)
select date_add(now(), interval 1 month);
-- 오늘 기준으로 다음달 출력 (한달 후)
select date_sub(now(), interval 1 week);
-- 오늘 기준으로 일주일 전 출력
▷ 월 0, 화 1, 수 2, 목 3, 금 4, 토 5, 일 6
select weekday(curdate()); -- 2출력 오늘은 수요일이기 때문
select adddate(curdate(), weekday(curdate()));
-- 오늘날짜 2024-03-13 수요일 기준으로 +2 하면 2024-03-15 출력
select adddate(curdate(), weekday(curdate())+1);
-- 오늘날짜 기준 수요일 2 더하고 +1 하면 2024-03-16 출력
select adddate(curdate(), -weekday(curdate()));
-- 오늘날짜 기준 수요일 2 빼면 2024-03-11 출력
select adddate(curdate(), -weekday(curdate())) as monday;
-- 뒤에 as는 그냥 이름 정한거 monday로
select curdate(), curtime(), now(); -- (현재 년월일), (현재 시간분초), (현재 년월일시분초)
select date_add('2010-12-31 23:59:59', INTERVAL 1 DAY);
-- 주어진 날짜에 (현재날짜 curdate대신 날짜 직접 적음) 하루 더하기 2011년 1월 1일
DateAdd 함수 - Microsoft 지원 - [ DateAdd 함수 참고 링크 ]
DateAdd 함수 - Microsoft 지원
구독 혜택을 살펴보고, 교육 과정을 찾아보고, 디바이스를 보호하는 방법 등을 알아봅니다. 커뮤니티를 통해 질문하고 답변하고, 피드백을 제공하고, 풍부한 지식을 갖춘 전문가의 의견을 들을
support.microsoft.com
[ GROUP BY 및 HAVING 그리고 집계 함수 ]
▷ max 최대값, min 최솟값
select max(enr_grade), min(enr_grade) from enrol;
select max(stu_weight), min(stu_weight) from student where stu_dept = '기계' ;
▷ count ( count는 null 값 포함하지 않고 카운트 )
select count(*), count(stu_height) from student;
-- * 전체 카운트 / stu_height만 카운트
select count(stu_dept), count(distinct stu_dept) from student; -
-- stu_dept 카운트 / stu_dept 중복제거 후 카운
▷ group by ( select ~ from ~ where ~ group by -> group by는 where보다 뒤에 젤 뒤에 위치 )
select stu_dept, count(*) from student group by stu_dept;
-- stu_dept기준으로 그룹핑
select stu_dept, stu_grade, count(*) from student group by stu_dept, stu_grade;
-- group by 2개 설정
select stu_dept, count(*) from student where stu_weight >=50 group by stu_dept;
-- (group by stu_dept)학과를 기준으로 (where stu_weight >=50)몸무게50이상인 (count(*))학생 수 뽑아내는 함수
select stu_dept, avg(stu_weight) from student group by stu_dept;
-- (group by stu_dept)학과를 기준으로 avg(stu_weight)을 구하는함수 (만약몸무게에 null 값이있다면 avg부정확)
select stu_dept, format(avg(stu_height),0) from student group by stu_dept;
-- avg 소수점 없애고 싶을때 format 함수 응용
▷ having
select stu_grade, format(avg(stu_height),1) from student where stu_dept = '기계'
group by stu_grade having (avg(stu_height))>=160;
-- 학과는 기계학과 이면서, 학년별로 평균키가 160이상인 평큔 키 값 출력
select stu_dept, max(stu_height) from student
group by stu_dept having max(stu_height) >= 175;
-- 학과별로 그룹핑해서 그 중 키가 최대키가 175이상인 학과와 학과에서 가장 키가 큰 수치를 출력

[ 부질의 ( 서브쿼리 ) ]
▷ select문 안에 ( select문 )
select stu_height from student where stu_name = '옥성우';
-- 옥성우 학생의 키
select stu_name from student where stu_height >
(select stu_height from student where stu_name = '옥성우');
-- 옥성우 학생보다 키 큰 학생의 이름 출력
select stu_name from student where stu_weight =
(select stu_weight from student where stu_name = '박희철') and stu_name <> '박희철' ;
-- 박희철 학생과 몸무게가 같은 학생의 이름 출력
select * from student where stu_height > (select avg(stu_height) from student);
-- 평균 키보다 큰 학생의 정보 출력
select * from student where stu_height > all(select avg(stu_height) from student group by stu_dept);
-- 학과별 평균 키보다 큰 학생의 정보 출력
select * from student where stu_class
in(select stu_class from student where stu_dept='컴퓨터정보') and stu_dept <>'컴퓨터정보';
[ Join 함수 ]
※ join ( 조인) : 상호 관련성을 갖는 두 개 이상의 테이블로부터 새로운 테이블을 생성하는 데 사용된다.
[ 내부 조인 ]
: 테이블의 공통속성을 출력하는 것
▷ inner join ( equi join 이퀴 조인 ) ☆★ : where절에서 = 연산자 사용
select stu.stu_no, stu_name, stu_dept, enr_grade from student stu, enrol en where stu.stu_no = en.stu_no;
-- from student stu, enrol en 별명으로 접근 가능 ( 속성과 달리 테이블명은 as를 쓰지 않음)
select s.stu_no, s.stu_name from student s, enrol e where s.stu_no = e.stu_no and sub_no = 101;
-- 과목번호 101번을 수강하고 있는 학생의 학번, 이름 출력
select stu_name, enr_grade from student s, enrol e where s.stu_no = e.stu_no and enr_grade >= 70;
-- 점수가 70점 이상인 학생 이름 검색
select stu_name from student s, enrol e, subject su
where su.sub_no=e.sub_no and e.stu_no=s.stu_no and sub_prof='강종영';
-- 강종영 교수가 강의하는 과목을 수강하는 학생의 이름 검색(equi join) => 테이블조인 3개 필요
▷ natural join ( 자연 조인 )
select stu.stu_no, stu_name, stu_dept, enr_grade from student stu natural join enrol en;
-- 스튜던드 필드와 인롤 필드 겹치는거 자연적으로 조인
select * from student natural join enrol;
-- 학생테이블과 수강테이블을 natural join해라
select sub_name, enro.stu_no, enr_grade from subject natural join enrol;
-- 과목 이름과, 학번, 점수를 검색해라 (natural join)
select stu_name, enr_grade from student natural join enrol where enr_grade <=70;
-- 점수가 70점 이하인 학생 이름 검색 (natural join)
▷ using
select stu.stu_no, stu_name, stu_dept, enr_grade from student stu join enrol using(stu_no);
select sub_name, enrol.stu_no, enr_grade from subject join enrol using(sub_no);
-- 과목이름과 학번, 점수를 검색해라
select stu_name, enr_grade from student join enrol using(stu_no) where enr_grade >= 60;
-- 점수가 60점 이상인 학생 이름 검색 (join using)
▷ join on
select stu.stu_no, stu_name, stu_dept, enr_grade from student stu join enrol en on stu.stu_no = en.stu_no;
[ 외부 조인 ] on
: 한쪽에는 데이터가 있고 다른 쪽에는 데이터가 없는 경우 데이터가 있는 쪽
테이블의 내용을 모두 출력한다. ( 내부조인은 공통성이 없으면 출력되지 않음 )
공통적이지 않은 과목번호는 합쳐지지 않음 이것을 합치게끔 하는게 외부조인
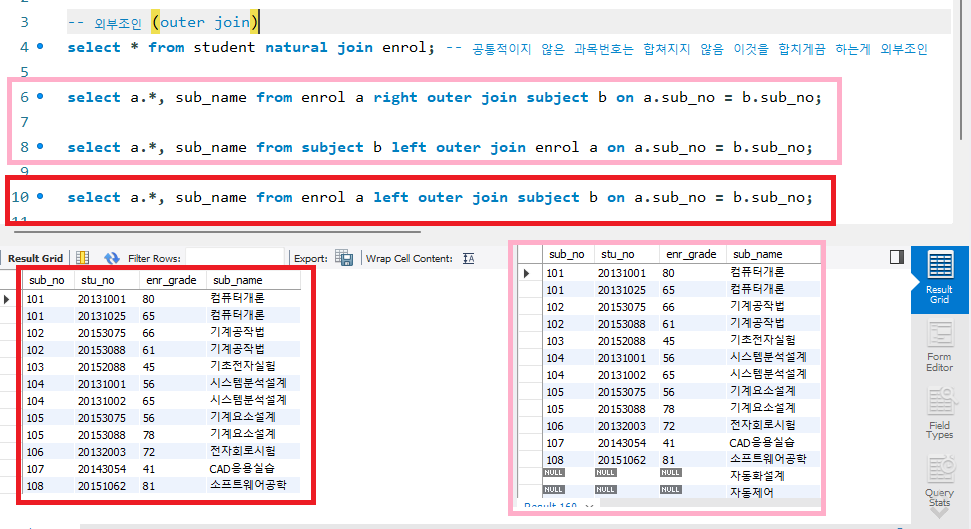
▷ left outer join : 왼쪽에 있는 테이블의 모든 결과를 가져온 후 오른쪽 테이블의 데이터를 매칭
select a.*, sub_name from subject b left outer join enrol a on a.sub_no = b.sub_no;
-- 왼쪽 테이블 기준으로 오른쪽 테이블을 합친다.
select a.*, sub_name from enrol a left outer join subject b on a.sub_no = b.sub_no;
▷ right outer join : 오른쪽에 있는 테이블의 모든 결과를 가져온 후 왼쪽 테이블의 데이터를 매칭
select a.*, sub_name from enrol a right outer join subject b on a.sub_no = b.sub_no;
-- 오른쪽 테이블 기준으로 왼쪽 테이블을 합친다.
[ 교차조인 ]
▷cross join
- 테이블의 모든 행이 각각 한번 씩 조인되어 모든 경우의 수 조합 됨
select student.*, enrol.* from student cross join enrol;
[ 셀프조인 ]
▷self join
select a.empno as 사원번호, a.ename as 사원이름, b.empno as 상급자사원번호, b.ename as 상급자이름
from emp a join emp b on a.mgr=b.empno;
-- emp가 smith인 사람의 상급자번호 7902와 상급자이름은 ford 알아내는 작업
[ select ~ from ; 을 이용한 총 복습 ]
use yujung;
select *from student;
select *from subject;
select *from enrol;
select stu_no, stu_name from student;
select stu_dept from student;
-- 중복제거(distinct)
select distinct stu_dept from student;
select distinct stu_grade, stu_class from student;
-- 원하는 별명(alias)으로 데이터 가져오기
-- 학번, 과목번호, 성적 가져오기
select stu_no, sub_no,enr_grade+10 from enrol;
select stu_no as ID, stu_name as name from student;
-- as 뒤에 원하는 필드명 지정 가능
-- 두개 이상의 열을 합쳐서 검색
-- 학과, 학생이름 추출 -> 학생테이블로부터
select stu_dept, stu_name from student;
select concat(stu_dept,stu_name) as 학과성명 from student;
select concat(stu_dept,' ',stu_name,'입니다') as 학과성명 from student;
-- where절 사용
select stu_name, stu_dept, stu_grade, stu_class from student where stu_dept = '컴퓨터정보';
-- 두가지 조건이 맞아야 출력 되는 and 연산자
select stu_name, stu_dept, stu_grade, stu_class from student
where stu_dept = '컴퓨터정보' and stu_grade=2;
-- 원하는 만큼만 데이터 가져오기
select * from student limit 5;
select * from student;
select * from student limit 1,5; -- 인덱스 1부터 5개
-- 범위조건
select * from student where stu_weight between 60 and 70;
select * from student where stu_no between '20140001' and '20149999';
-- % : 0개 이상 문자
-- _ : 1개 이상 문자
select stu_no, stu_name, stu_dept from student where stu_name like '김%'; -- 성김씨만추출 김%는뒤에뭐가와도상관x 첫글자가김으로만시작하면됨
select stu_no, stu_name, stu_dept from student where stu_name like '_수%'; -- _수_ 도 무관 왜냐면 수 뒤에 한글자니깐 ! 심수정 출력
select * from student where stu_no like '2014%'; -- 학번이 2014로 시작하는 모든 학번 출력
select stu_no, stu_name, stu_dept from student where stu_dept in('컴퓨터정보', '기계'); -- in 또는 이라는 뜻 = or
select * from student where stu_height >= 170;
-- 이외
select * from student where not stu_dept = '컴퓨터정보'; -- 이외라는 뜻 컴퓨터정보만빼고
SELECT * FROM student WHERE stu_dept not in('컴퓨터정보'); -- not in도 가능
SELECT * FROM student WHERE stu_dept <>('컴퓨터정보'); -- <>도 가능
-- null 값 존재 여부
select stu_no, stu_name, stu_height from student where stu_height is null; -- 키값이 비어있는 조건을 찾는 작업
select stu_no, stu_name, stu_height from student where stu_height is not null; -- 키값이 비어있는 조건을 빼고 찾는 작업
-- ifnull/nullif
-- ifnull(수식1, 수식2) : 수식 1이 null이 아니면 수식 1 반환, null이면 수식 2 반환
select ifnull(stu_height,0) from student;
-- nullif(인수1, 인수2) : 두개값 비교해서 값 같으면 null반환, 아니면 인수1 반환
select ifnull(nullif('A','A'),'널값'); -- 널값 출력 ifnull(null,'널값');
-- 순서화(정렬)
select stu_no, stu_name from student order by stu_no;
select stu_no, stu_name from student order by stu_no desc;
-- 별칭이 붙어있는 열을 기준으로 정렬
select stu_no, stu_name, stu_dept, stu_weight-5
as target from student order by target;
-- 열의 순서번호 이용하여 정렬
select stu_no, stu_name, stu_dept, stu_weight-5
as target from student order by 3; -- stu_dept기준으로 정렬
select stu_no, stu_name, stu_dept, stu_weight-5
as target from student order by stu_weight-5; -- 몸무게에서 -5한 값을 기준으로 정렬하겠다
select stu_no, stu_name, stu_dept, stu_weight-5
as target from student order by stu_dept, target; -- 학과가 먼저 정렬되고 그 이후 target 정렬됨
select stu_no, stu_name, stu_dept, stu_weight-5
as target from student order by stu_dept desc, target desc; -- 둘다내림차순 하려면 둘다 desc 적어줘야함
-- max,min
select max(enr_grade), min(enr_grade) from enrol;
select max(stu_weight), min(stu_weight) from student where stu_dept = '기계' ;
-- count (null값은 포함하지 않고 카운트)
select count(*), count(stu_height) from student;
select count(stu_dept), count(distinct stu_dept) from student; -- 중복 제거 카운트
-- group by
select stu_dept, count(*) from student group by stu_dept; -- stu_dept기준으로 그룹핑
select stu_dept, stu_grade, count(*) from student group by stu_dept,stu_grade; -- group by 2개 설정
select stu_dept, count(*) from student where stu_weight >=50 group by stu_dept;
select stu_dept, avg(stu_height) from student group by stu_dept;
select stu_dept, format(avg(stu_height),0) from student group by stu_dept; -- format(숫자, 소수점 자리수)
-- having 절
select stu_grade, format(avg(stu_height),1) from student where stu_dept = '기계'
group by stu_grade having (avg(stu_height))>=160;
select stu_dept, max(stu_height) from student
group by stu_dept having max(stu_height) >= 175;
-- 부질의
select stu_height from student where stu_name = '옥성우'; -- 옥성우 학생의 키
select stu_name from student where stu_height >
(select stu_height from student where stu_name = '옥성우'); -- 옥성우 학생보다 키 큰 학생의 이름 출력
select stu_name from student where stu_weight =
(select stu_weight from student where stu_name = '박희철') and stu_name <> '박희철'; -- 박희철 학생과 몸무게가 같은 학생의 이름 출력
select * from student where stu_height > (select avg(stu_height) from student); -- 평균 키보다 큰 학생의 정보 출력
select * from student where stu_height > all(select avg(stu_height) from student group by stu_dept);
select * from student where stu_class
in(select stu_class from student where stu_dept='컴퓨터정보') and stu_dept <>'컴퓨터정보';
[ 사칙연산 복습 ]
-- 사칙연산
select 1+2; -- 3출력
select 3*(2+4)/2, 'hi';
select 10%3;
-- 문자열에 사칙연산을 가하면 0으로 인식
select 'AB' + 3; -- 3출력
select 'AB' * 3; -- 0출력
-- true는 1 false는 0
select true, false; -- true는 1 false는 0 출력
select true is true; -- true니깐 1출력
select 2+4=6 or 2*4=8; -- or니깐 둘중 하나만 맞아도 참. 즉, true 1 출력
select 'B'='b'; -- MySQL의 기본 사칙 연산자는 대소문자 구분하지 않는다. 즉, true 1 출력
select 10 between 15 and 20; -- flase 0 출력
select 'apple' not between 'banana' and 'computer'; -- ture 1 출력
select 1+2 in(2,3,4);
select 'hi' in (1,true,'hi'); -- hi가 in안에 들어있냐 -> true 1 출력
-- round (반올림)
select round(345.678),round(345.678,0),round(345.678,1),round(345.678,2),
round(345.678,-1); -- 346, 346, 345.7, 345.68, 350 출력
-- truncate(버림,소숫점자리)
select truncate(1234.56789, 1), truncate(1234.56789, 2), truncate(1234.56789, -1);
-- 1234.5, 1234.56, 1230 출력
select truncate(1234.56789, -2), truncate(1234.56789, -3); -- 1200, 1000 출력
-- upper (대문자), lower (소문자)
select upper('korea');
select lower('KOREA');
-- abs(절대값), pow(제곱), power(제곱), sqrt(루트), concat(값 연결)
select abs(1), abs(-1), abs(3-10);
select pow(2,3), power(5,2), sqrt(16);
select concat('hello',' ','2024','03','13');
-- concat_ws (괄호안에 내용이 첫번째 매개변수로 이어 붙여짐)
select concat_ws('-','2024',3,13,'PM'); -- 2024-3-13-PM으로 출력
select substr('ABCDEFGH', 3),substr('ABCDEFGH',3,2),substr('ABCDEFGH', -4),substr('ABCDEFGH', -4,2);
-- 3번째부터 끝까지 CDEFGHC, 3번째 C부터 글자 2개 CD, 뒤에서부터 4글자 EFGH, 뒤에서4번째 E부터 2개 EF
select length('ABCDEFGH'), -- 문자열의 바이트 길이 / 영어바이트는1임. 8출력
char_length('ABC'); -- 문자열의 문자길이 3 출력
select length('안녕하세요'), char_length('안녕하세요'); -- 한글바이트 15 출력, char 문자열의 길이 5출력
select char_length('안녕하세요'),character_length('안녕하세요'); -- 똑같은 결과 똑같은 말임
select concat('|', ltrim(' hello'), '|'), -- left trim 왼쪽공백제거 -> |hello| 출력
concat('|', rtrim(' hello '), '|'), -- right trim 오른쪽공백제거 -> |hello| 출력
concat('|', trim(' hello '), '|'); -- trim 양쪽공백제거 -> |hello| 출력 / 공백 길이는 상관 없이 전부 제거
-- lpad(S, N, P) S가 N이 될 때 까지 P를 왼쪽에 이어 붙이는 작업
select lpad('ABC',5,'#'); -- ##ABC 출력
-- rpad(S, N, P) S가 N이 될 때 까지 P를 오른쪽에 이어 붙이는 작업
select rpad('ABC',5,'@'); -- ABC@@ 출력
-- replace (내용,old,new) 내용에 old가 new로 바뀜
select replace ('버거킹에서 버거킹 햄버거 먹었다','버거킹','맘스터치'); -- 맘스터치에서 맘스터치 햄버거 먹었다 출력
-- instr(S,s) S중 s의 첫 위치 반환하는 함수
select instr('ABCDE','ABC'), instr('ABCDE','BC'); -- ABCDE중에서 ABC의 첫위치 1 출력 / ABCDE중 BC의 첫위치2 출력
-- cast(A as T) : A를 T 자료형으로 변환 즉, 형변환 함수
select '01' = '1', -- false 0 출력
cast('01' as decimal) = cast('1' as decimal); -- cast 형변환 ! '01' 문자를 as decimal로 true 1 출력
-- convert(A,T) : A를 T 자료형으로 변환
select '01' = '1', -- false 0 출력
convert('01', decimal) = convert('1', decimal); -- cast보다 conver가 더 많이 사용 됨 true 1 출력
-- 학생들의 성별을 소문자로 검색
select distinct lower(stu_gender) from student;
-- 학생들의 학과, 이름을 연결하여 검색
select concat(stu_dept,' ',stu_name) from student;
-- substr 학생들의 이름과 이름의 첫 2글자 검색
select substr(stu_name,1,2) from student; -- 1 첫번째 글짜부터 2 두개글까까지
-- 학생들의 이름, 학과, 그리고 학과의 두 번째부터 1자리 검색
select stu_name, stu_dept, substr(stu_dept,2,1) from student;
[ 날짜 함수 복습 ]
-- 날짜함수
select date(now()); -- 연월일
select time(now()); -- 시분초
select timestamp(now()); -- 현재 연월일 시분초
select sysdate(); -- 현재 연월일 시분초
select curdate(); -- 연월일
-- adddate(date, interval expr)
select adddate(now(), interval 1 day); -- 오늘 기준으로 다음날 출력 (24시간 후)
select adddate(now(), interval 1 month); -- 오늘 기준으로 다음달 출력 (한달 후)
select date_add(now(), interval 1 month);-- 오늘 기준으로 다음달 출력 (한달 후) 위에꺼랑 똑같음 뭘 사용하던 상관 x
select date_sub(now(), interval 1 week); -- 오늘 기준으로 일주일 전 출력
select adddate(curdate(), -weekday(curdate())) as monday; -- 이번주 월요일 (현재날짜를 기준으로 weekday요일을 뽑기 monday)
select adddate(curdate(), weekday(curdate())) as monday; -- 다음주 월요일 현재 날짜(curdate())에서 현재 요일(weekday(curdate()))을 더한 값을 월요일의 날짜로 계산하는 것입니다.
select date_add('2010-12-31 23:59:59', interval 1 day); -- 주어진 날짜에(현재날짜 curdate대신 날짜 직접 적음)하루 더하기 2011년 1월 1일
select curdate(), curtime(), now(); -- (현재 년월일), (현재 시간분초), (현재 년월일시분초)
-- 날짜함수
select date(now()); -- 연월일
select time(now()); -- 시분초
select timestamp(now());-- 현재 연월일 시분초
select sysdate(); -- 현재 연월일 시분초
select curdate(); -- 연월일
select adddate(now(), interval 1 day); -- 오늘기준으로 다음 날 출력
select date_add(now(), interval 1 month);-- 오늘기준으로 다음 달 출력
select date_sub(now(), interval 1 week); -- 오늘 기준으로 일주 전 출력
SELECT DATE_ADD('2010-12-31 23:59:59', INTERVAL 1 DAY); -- 주어진 날짜에 (현재날짜 curdate대신 날짜 직접 적음) 하루 더하기 2011년 1월 1일
select curdate(), curtime(), now(); -- (현재 년월일), (현재 시간분초), (현재 년월일시분초)
-- 월 0, 화 1, 수 2, 목 3, 금 4, 토 5, 일 6
-- adddate (date,interval) :
select weekday(curdate()); -- 2출력 오늘은 수요일이기 때문
select adddate(curdate(), -weekday(curdate())); -- 2024-03-13 수요일 오늘날짜 기준으로 수요일 2 빼면 2024-03-11 출력
select adddate(curdate(), weekday(curdate())+1); -- 2024-03-13 수요일 오늘날짜 기준으로 수요일 2 더하고 +1 하면 2024-03-16 출력
select adddate(curdate(), weekday(curdate())); -- 오늘날짜 수요일 기준으로 +2 2024-03-15 출력
select adddate(curdate(), -weekday(curdate())) as monday; -as는 그냥 monday이름 정해준것
select adddate(curdate(), weekday(curdate())) as monday;
[ Join 복습 ]
-- inner join (equi join)
-- from student stu, enrol en 별명으로 접근 가능
select stu.stu_no, stu_name, stu_dept, enr_grade
from student stu, enrol en where stu.stu_no = en.stu_no;
select s.stu_no, s.stu_name from student s, enrol e
where s.stu_no=e.stu_no and sub_no=101; -- 과목번호 101번을 수강하고 있는 학생의 학번, 이름 출력
select stu_name, enr_grade from student s, enrol e
where s.stu_no=e.stu_no and enr_grade >= 70; -- 점수가 70점 이상인 학생 이름 검색 (equi join)
select stu_name from student s, enrol e, subject su
where su.sub_no=e.sub_no and e.stu_no=s.stu_no and sub_prof='강종영'; -- 강종영 교수가 강의하는 과목을 수강하는 학생의 이름 검색(equi join) 테이블조인 3개 필요
-- natural join (자연 조인)
select stu.stu_no, stu_name, stu_dept, enr_grade
from student stu natural join enrol en; -- 스튜던드 필드와 인롤 필드 겹치는거 자연적으로 조인
select * from student natural join enrol; -- 학생테이블과 수강테이블을 natural join해라
select sub_name, enro.stu_no, enr_grade
from subject natural join enrol; -- 과목 이름과, 학번, 점수를 검색해라 (natural join)
select stu_name, enr_grade from student
natural join enrol where enr_grade <=70; -- 점수가 70점 이하인 학생 이름 검색 (natural join)
-- using
select stu.stu_no, stu_name, stu_dept, enr_grade
from student stu join enrol using(stu_no);
select sub_name, enrol.stu_no, enr_grade
from subject join enrol using(sub_no); -- 과목이름과 학번, 점수를 검색해라
select stu_name, enr_grade
from student join enrol using(stu_no) where enr_grade >= 60; -- 점수가 60점 이상인 학생 이름 검색 (join using)
-- join on
select stu.stu_no, stu_name, stu_dept, enr_grade
from student stu join enrol en on stu.stu_no = en.stu_no;
-- cross join (교차조인)
-- 테이블의 모든 행이 각각 한번 씩 조인되어 모든 경우의 수 조합 됨
select student.*, enrol.* from student cross join enrol;
-- 외부조인 (outer join)
select * from student natural join enrol; -- 공통적이지 않은 과목번호는 합쳐지지 않음 이것을 합치게끔 하는게 외부조인
select a.*, sub_name from enrol a right outer join subject b on a.sub_no = b.sub_no;
-- 오른쪽 테이블 기준으로 왼쪽 테이블을 합친다.
select a.*, sub_name from subject b left outer join enrol a on a.sub_no = b.sub_no;
-- 왼쪽 테이블 기준으로 오른쪽 테이블을 합친다.
select a.*, sub_name from enrol a left outer join subject b on a.sub_no = b.sub_no;
-- self join (셀프조인)
select a.empno as 사원번호, a.ename as 사원이름, b.empno as 상급자사원번호, b.ename as 상급자이름
from emp a join emp b on a.mgr=b.empno;
-- emp가 smith인 사람의 상급자번호 7902와 상급자이름은 ford 알아내는 작업
[ 문제풀이 1 - student, subject, enrol 테이블 표를 활용한 ]
create table student(
stu_no char(9),
stu_name varchar(12),
stu_dept varchar(20),
stu_grade int(1),
stu_class char(1),
stu_gender char(1),
stu_height decimal(5,2),
stu_weight decimal(5,2),
constraint p_stu_no primary key(stu_no));
desc student;
create table subject(
sub_no char(3),
sub_name varchar(30),
sub_prof varchar(12),
sub_grade int(1),
sub_dept varchar(20),
constraint p_sub_no primary key(sub_no));
desc subject;
create table enrol(
sub_no char(3),
stu_no char(9),
enr_grade int(3),
constraint p_course primary key(sub_no,stu_no));
desc enrol;
insert into student values(20153075,'옥한빛','기계',1,'C','M',177,80);
insert into student values(20153088,'이태연','기계',1,'C','F',162,50);
insert into student values(20143054,'유가인','기계',2,'C','F',154,47);
insert into student values(20152088,'조민우','전기전자',1,'C','M',188,90);
insert into student values(20142021,'심수정','전기전자',2,'A','F',167,45);
insert into student values(20132003,'박희철','전기전자',3,'B','M',null,63);
insert into student values(20151062,'김인중','컴퓨터정보',1,'B','M',166,67);
insert into student values(20141007,'진현무','컴퓨터정보',2,'A','M',174,64);
insert into student values(20131001,'김종헌','컴퓨터정보',3,'C','M',null,72);
insert into student values(20131025,'옥성우','컴퓨터정보',3,'A','F',172,63);
insert into enrol values('101','20131001',80);
insert into enrol values('104','20131001',56);
insert into enrol values('106','20132003',72);
insert into enrol values('103','20152088',45);
insert into enrol values('101','20131025',65);
insert into enrol values('104','20131002',65);
insert into enrol values('108','20151062',81);
insert into enrol values('107','20143054',41);
insert into enrol values('102','20153075',66);
insert into enrol values('105','20153075',56);
insert into enrol values('102','20153088',61);
insert into enrol values('105','20153088',78);
insert into subject values('111','데이터베이스','이재영',2,'컴퓨터정보');
insert into subject values('110','자동제어','정순정',2,'전기전자');
insert into subject values('109','자동화설계','박민영',3,'기계');
insert into subject values('101','컴퓨터개론','강종영',3,'컴퓨터정보');
insert into subject values('102','기계공작법','김태영',1,'기계');
insert into subject values('103','기초전자실험','김유석',1,'전기전자');
insert into subject values('104','시스템분석설계','강석현',3,'컴퓨터정보');
insert into subject values('105','기계요소설계','김명성',1,'기계');
insert into subject values('106','전자회로시험','최영민',3,'전기전자');
insert into subject values('107','CAD응용실습','구봉규',2,'기계');
insert into subject values('108','소프트웨어공학','권민성',1,'컴퓨터정보');-- 6. 과목들의 과목번호와 과목이름을 검색하라.
select sub_no, sub_name from subject;
-- 7. 학생들의 학번과 이름, 성별을 검색하라.
select stu_no, stu_name, stu_gender from student;
-- 8. 학생들의 모든 정보를 검색하라.
select * from student;
-- 9. 학생들의 학번과 이름, 학년, 반을 검색하라.
select stu_no, stu_name, stu_grade, stu_class from student;
-- 10. 과목들의 과목이름과 교수이름을 검색하라.
select sub_name, sub_prof from subject;
-- 11. 과목번호, 학번, 점수를 검색하라.
select sub_no, stu_no, enr_grade from enrol;
-- 12. 학생들의 체중과 신장을 학번, 이름과 함께 검색하라.
select concat(stu_no, stu_name, stu_height, stu_weight) as 학생정보 from student;
-- 13. 학생들의 학과 중복을 제거하고 검색하라.
select distinct stu_dept from student;
-- 14. 학생들의 성별 중복을 제거하고 검색하라.
select distinct stu_gender from student;
-- 15. 학생들의 학년 중복을 제거하고 검색하라.
select distinct stu_grade from student;
-- 16. 학생들의 학과, 학년 중복을 제거하고 검색하라.
select distinct stu_dept, stu_grade from student;
-- 17. 학생들의 학과, 반 중복을 제거하고 검색하라.
select distinct stu_dept, stu_class from student;
-- 18. 학생들의 체중을 5만큼 증가시킨 값을 검색하라
select stu_weight+5 from student;
-- 19. 학생들의 체중을 5만큼 감소시킨 값을 검색하라.
select stu_weight-5 from student;
-- 20. 학생들의 학번과 이름을 별칭 "학번", "이름"으로 부여하여 검색하라.
select stu_no as 학번, stu_name as 이름 from student;
-- 21. 수강(enrol)테이블의 모든 정보를 검색하라.
select * from enrol;
-- 22. 학생 테이블에서 학과명과 이름을 합쳐서 검색하라.
select concat(stu_dept, stu_name) from student;
-- 23. 학생의 이름과 학과를 '컴퓨터정보과 옥한빛입니다'식으로 검색하라.
select concat(stu_dept, '과 ', stu_name,'입니다') from student;
-- 24. 컴퓨터정보 학생들을 검색하라.
select * from student where stu_dept = '컴퓨터정보';
-- 25. 기계과 학생들을 검색하라.
select * from student where stu_dept = '기계';
-- 26. 전기전자과 학생들을 검색하라.
select * from student where stu_dept ='전기전자';
-- 27. 신장이 170이상인 학생들을 검색하라.
select * from student where stu_height >= 170;
-- 28. 체중이 65이상인 학생들을 검색하라.
select * from student where stu_weight >= 65;
-- 29. 기계 학생들의 학번, 이름을 검색하라.
select stu_no, stu_name from student where stu_dept = '기계';
-- 30. 컴퓨터정보 학생들의 학번, 이름을 검색하라.
select stu_no, stu_name from student where stu_dept = '컴퓨터정보';
-- 31. 남학생의 이름을 검색하라.
select stu_name from student where stu_gender ='M';
-- 32. 전기전자과 이외 학생들의 모든 정보를 검색하라.
select * from student where not stu_dept = '전기전자';
-- 33. 점수가 80점 이상인 학생들의 학번을 검색하라.
select * from enrol where enr_grade >= 80;
-- 34. '김인중'학생의 모든 정보를 검색하라.
select * from student where stu_name = '김인중';
-- 35. '기계'과 이고 2학년인 학생들의 모든 정보를 검색하라.
select * from student where stu_dept ='기계' and stu_grade = 2;
-- 36. 성별이 여학생이며, 체중이 60이하인 학생을 모두 검색하라.
select *from student where stu_gender = 'f' and stu_weight<=60;
-- 37.'컴퓨터정보'외에 1학년 학생들의 이름을 검색하라.
select stu_name from student where stu_dept<>'컴퓨터정보' and stu_grade=1;
-- 38. 학과 중 '기계'이외의 학과를 검색하라.
select sub_dept from subject where not sub_dept='기계';
-- 39. 컴퓨터정보과 2학년 A반 학생의 이름을 검색하라.
select stu_name from student where stu_dept='컴퓨터정보' and stu_grade=2 and stu_class ='A';
-- 40. 신장이 160이상이며 170이하인 학생의 학번과 이름을 검색하라
select stu_no, stu_name from student where stu_height between 160 and 170;
-- 56번 학생들의 이름과 이름의 길이를 검색하라.
select stu_name , char_length(stu_name) from student;
-- 57번 학생들의 학과와 학과명의 길이를 검색하라.
select stu_dept , char_length(stu_dept) from student;
-- 58번 학생들의 이름에 '김'이 몇번째 있는지 검색하라.
select instr(stu_name,'김') from student;
-- 59번 학생의 이름을 15자리로 하고, 뒤에 '&'를 채워 검색하라.
select rpad(stu_name,15,'&') from student;
-- 60번 학생의 학과를 20자리로 하고, 앞에 '%'를 채워 검색하라.
select lpad(stu_dept,20,'%') from student;
-- 61번 학생의 학번, 이름, 신장을 검색하라. (신장은 첫번째 자리에서 반올림함)
select stu_no, stu_name, round(stu_height,0) from student;
-- 62번 학생의 학번, 이름, 신장을 검색하라. (신장은 두번째 자리에서 절삭함)
select stu_no, stu_name, truncate(stu_height,-2) from student;
-- 63번 체중을 30으로 나눈 나머지를 검색하라.
select (stu_weight%30) from student;
-- 64번 신장열의 값이 널인 학생의 경우 '미기록'으로 검색하라.
select ifnull(stu_height, '미기록') from student;
-- 68번 학생 중 키가 가장 큰 학생의 신장을 검색하라.
select max(stu_height) from student;
-- 69번 학생의 이름 중 MAX와 MIN값을 검색하라.
select max(stu_name), min(stu_name) from student;
-- 70번 학생테이블의 레코드(튜플)수를 검색하라.
select count(*) from student;
-- 71번 학과별 학생들의 인원수를 검색하라.
select stu_dept, count(*) from student group by (stu_dept);
-- 72번 학과별 학생들의 인원수를 인원수가 많은 순으로 검색하라.
SELECT stu_dept, count(*) FROM student GROUP BY stu_dept ORDER BY stu_dept DESC;
-- 73번 학년별 학생들의 인원수를 검색하라.
select stu_grade, count(*) from student group by stu_grade;
-- 74번 학과별 학년별 학생들의 평균 체중을 검색하라.
SELECT stu_dept, stu_grade, format(avg(stu_weight),1) FROM student GROUP BY stu_dept, stu_grade;
-- 75번 학과별 학년별 학생들의 학번의 MAX와 MIN값을 검색하라.
select stu_dept, stu_grade,max(stu_no), min(stu_no) from student group by stu_dept, stu_grade;
[ 심화 - 문제풀이 ]
-- 김종헌 학생의 평균 점수보다 높은 점수를 가진 학생의 학번과 이름을 검색해라.
SELECT s.stu_no, stu_name FROM student s, enrol e WHERE s.stu_no = e.stu_no
and enr_grade > ( SELECT avg(enr_grade) FROM enrol e GROUP BY stu_name = '김종헌');
-- 김인중 학생의 평균 점수보다 낮은 점수를 가진 학생의 학번과 이름을 검색해라.
SELECT s.stu_no, stu_name FROM student s, enrol e WHERE s.stu_no = e.stu_no
and enr_grade < ( SELECT avg(enr_grade) FROM enrol e GROUP BY stu_name = '김인중');
-- 전체 학생의 평균 점수보다 높은 점수를 가진 학생의 학번, 이름, 과목이름, 점수를 검색해라.
SELECT s.stu_no, stu_name, sub_name, enr_grade FROM student s, enrol e, subject su
WHERE s.stu_no = e.stu_no and e.sub_no = su.sub_no and enr_grade >
( SELECT avg(enr_grade) FROM enrol);
-- 점수가 각 학과 학생들의 평균 점수보다 높은 학생의 학번을 검색해라.
SELECT s.stu_no FROM student s, enrol e WHERE s.stu_no = e.stu_no
and enr_grade > (SELECT avg(enr_grade) FROM enrol GROUP BY stu_dept);
-- 기계과의 최고 점수 학생보다 최고 점수가 높은 학과의 학과명과 점수를 검색해라.
SELECT stu_dept, max(enr_grade) FROM student s, enrol e WHERE s.stu_no = e.stu_no
GROUP BY stu_dept HAVING max(enr_grade) > (SELECT max(enr_grade) FROM enrol
GROUP BY stu_dept HAVING stu_dept = '기계');
-- 컴퓨터정보과 학생들의 평균 점수를 구해 학생들의 학번과 이름 평균 점수를 성적 순으로 검색해라.
SELECT s.stu_no, stu_name, avg(enr_grade) FROM student s, enrol e WHERE s.stu_no = e.stu_no
GROUP BY s.stu_no ORDER BY avg(enr_grade) DESC;
-- 시스템분석설계 과목을 수강한 학생들의 학번, 이름, 점수를 성적 순으로 검색해라.
SELECT s.stu_no, stu_name, enr_grade FROM student s, enrol e, subject su
WHERE s.stu_no = e.stu_no and e.sub_no = su.sub_no
and sub_name = '시스템분석설계' ORDER BY enr_grade DESC;
-- 2과목 이상 수강한 학생들의 학번, 이름, 수강과목 수를 수강과목이 많은 순으로 검색해라.
SELECT s.stu_no, stu_name, count(e.stu_no) as 수강과목수 FROM student s, enrol e
WHERE s.stu_no = e.stu_no GROUP BY e.stu_no ORDER BY 수강과목수 DESC;
-- 1과목을 수강한 학생들의 학번, 이름을 학과별 학번 순으로 검색해라.
SELECT e.stu_no, stu_name FROM student s, enrol e WHERE s.stu_no = e.stu_no
GROUP BY e.stu_no HAVING count(e.stu_no) = 1 ORDER BY s.stu_no;
-- 컴퓨터개론과 시스템분석설계 과목을 수강하는 학생의 학번, 이름을 학번순으로 검색해라.
SELECT s.stu_no, stu_name FROM student s, enrol e, subject su
WHERE s.stu_no = e.stu_no and e.sub_no = su.sub_no
and sub_name = '컴퓨터개론' and sub_name = '시스템분석설계' ORDER BY s.stu_no;
[ 문제 풀이 2 - emp dept salgrade 테이블 표를 활용한 ]
use yujung;
create table emp(
empno int(4),
ename varchar(10),
job varchar(9),
mgr int(4),
foreign key(mgr) references emp(empno),
hiredate date,
sal decimal(7,2),
comm decimal(7,2),
deptno int(2),
constraint primary key pk_emp (empno));
create table dept(
deptno int(2),
dname varchar(14),
loc varchar(13),
constraint primary key pk_dept(deptno));
create table salgrade(
grade decimal(7,2),
losal decimal(7,2),
hisal decimal(7,2));
insert into emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
insert into emp values(7566,'JONES','MANAGER',7839,'1981-4-2',2975,NULL,20);
insert into emp values(7698,'BLAKE','MANAGER',7839,'1981-5-1',2850,NULL,30);
insert into emp values(7782,'CLARK','MANAGER',7839,'1981-6-9',2450,NULL,10);
insert into emp values(7788,'SCOTT','ANALYST',7566,'1987-7-13',3000,NULL,20);
insert into emp values(7902,'FORD','ANALYST',7566,'1981-12-3',3000,NULL,20);
insert into emp values(7499,'ALLEN','SALESMAN',7698,'1981-2-20',1600,300,30);
insert into emp values(7521,'WARD','SALESMAN',7698,'1981-2-22',1250,500,30);
insert into emp values(7654,'MARTIN','SALESMAN',7698,'1981-9-28',1250,1400,30);
insert into emp values(7844,'TURNER','SALESMAN',7698,'1981-9-8',1500,0,30);
insert into emp values(7900,'JAMES','CLERK',7698,'1981-12-3',950,NULL,30);
insert into emp values(7934,'MILLER','CLERK',7782,'1982-1-23',1300,NULL,10);
insert into emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
insert into emp values(7876,'ADAMS','CLERK',7788,'1987-07-13',1100,NULL,20);
insert into dept values(10,'ACCOUNTING','NEW YORK');
insert into dept values(20,'RESEARCH','DALLAS');
insert into dept values(30,'SALES','CHICAGO');
insert into dept values(40,'OPERATIONS','BOSTON');
insert into salgrade values(1,700,1200);
insert into salgrade values(2,1201,1400);
insert into salgrade values(3,1401,2000);
insert into salgrade values(4,2001,3000);
insert into salgrade values(5,3001,9999);use yujung;
-- 1번 ⦁ 사원 테이블의 구조를 검색하라.
select * from emp;
-- 2번 ⦁ 부서 테이블의 구조를 검색하라.
select * from dept;
-- 3번 ⦁ 급여 테이블의 구조를 검색하라.
select * from salgrade;
-- 4번 ⦁ 사원들의 사원번호, 사원이름, 사원직무를 검색하라.
select empno, ename, job from emp;
-- 5번 ⦁ 부서의 부서번호와 부서이름을 검색하라.
select deptno, dname from dept;
-- 6번 ⦁ 부서의 부서이름과 지역을 검색하라.
select dname, loc from dept;
-- 7번 ⦁ 사원들의 급여와 커미션을 검색하라.
select sal, comm from emp;
-- 8번 ⦁ 사원들의 입사일 중복을 제거하고 검색하라.
select distinct hiredate from emp;
-- 9번 ⦁ 사원들의 상급자사원번호(mgr)중복을 제거하고 검색하라.
select distinct mgr from emp;
-- 10번 ⦁ 사원들의 부서번호 중복을 제거하고 검색하라.
select distinct deptno from emp;
-- 11번 ⦁ 사원들의 이름과 6개월 급여의 합을 검색하라.
-- 12번 ⦁ 사원들의 6개월 커미션(comm)의 합을 검색하라.
-- 13번 ⦁ 사원이름을 ‘name’으로 사원의 급여를 ‘salary’로 열의 이름을 부여하여 검색하라.
select ename as 사원이름, sal as 사원의급여 from emp;
-- 14번 ⦁ 사원의 사원번호, 사원이름, 입사일, 부서번호를 한글로 바꾸어 검색하라.
select empno as 사원번호, ename as 사원이름, hiredate as 입사일, deptno as 부서번호 from emp;
-- 15번 ⦁ 부서번호, 부서이름, 지역을 한글 제목으로 검색하라.
select deptno as 부서번호, dname as 부서이름, loc as 지역 from dept;
-- 16번 ⦁ 사원의 사원직무와 사원이름을 합쳐서 검색하라.
select concat(job, ' ' ,ename) from emp;
-- 17번 ⦁ 입사일(hiredate) 사원이름을 ’80-12-17에 입사한 SMITH입니다’ 식으로 검색하라.
select concat(hiredate,'에 입사한 ',ename,'입니다') from emp;
-- 18번 ⦁ 10번 부서에 근무하는 사원이름을 검색하라.
select dname from dept where deptno = '10' ;
-- 19번 ⦁ 급여가 2000 이상인 사원들의 사원번호, 사원이름을 검색하라.
select empno,ename from emp where sal >= 2000 ;
-- 20번 ⦁ 사원직무가 “CLERK”인 사원들의 사원번호, 사원이름을 검색하라.
select empno,ename from emp where job='clerk';
-- 21번 ⦁ 1980년 12월 17일에 입사한 사원이름을 검색하라
select ename from emp where hiredate = '1980-12-17';
-- 22번 ⦁ 부서번호 30이외의 부서이름과 지역을 검색하라.
select dname, loc from dept where not deptno = '30';
-- 23번 ⦁ 급여등급이 5인 급여의 상위급여와 하위급여를 검색하라.
select losal, hisal from salgrade where grade ='5';
-- 24번 ⦁ ‘WARD’사원의 모든 정보를 검색하라.
select * from emp where ename = 'ward';
-- 25번 ⦁ 20부터 외에 근무하는 MANAGER의 사원이름을 검색하라.
select ename from emp where not deptno = '20' and job = 'manager';
-- 26번 ⦁ BOSTON이외 지역에 있는 부서이름을 검색하라.
select dname from dept where not loc = 'boston';
-- 27번 ⦁ SALEMAN이며 급여가 1500이상인 사원이름을 검색하라.
select ename from emp where job = 'salesman' and sal >= 1500;
-- 28번 ⦁ 급여가 1000이상이며, 2500이하인 사원의 사원번호, 사원이름, 급여를 검색하라.
select empno, ename, sal from emp where sal between 1000 and 2500 ;
-- 29번 ⦁ 사원번호가 75XX인 사원의 사원번호, 사원이름, 부서번호를 검색하라.
select empno, ename, deptno from emp where empno like '75%';
-- 30번 ⦁ 근무하는 사원들의 사부서번호가 10 또는 30에 원이름과 급여를 검색하라.
select ename, sal from emp where deptno ='10' or deptno= '30';
-- 31번 ⦁ 상급자사원번호가 76으로 시작하는 사원들의 사원이름을 검색하라.
select ename from emp where mgr like '76%';
-- 32번 ⦁ 사원번호가 79로 시작하는 사원들의 사원이름, 급여, 커미션을 검색하라.
select ename,sal,comm from emp where empno like '79%';
-- 33번 ⦁ 1981년 2월에 입사한 사원의 사원번호, 사원이름, 부서번호를 검색하라.
select empno, ename, deptno from emp where hiredate like '1981-02%';
-- 34번 ⦁ 사원이름 중간에 ‘A’가 들어있는 사원의 사원번호와 사원이름을 검색하라.
select empno, ename from emp where ename like '_%A%_'; -- 사원이름 중간에 ‘A’가 들어있는 사원의 사원번호와 사원이름을 검색하라.
-- 35번 ⦁ 상급자사원번호가 NULL인 사원의 사원번호와 사원이름을 검색하라.
select empno, ename from emp where mgr is null;
-- 36번 ⦁ 상급자사원번호가 NULL이 아닌 사원의 사원번호, 이름, 상급자사원번호를 검색하라.
select empno, ename, mgr from emp where mgr is not null;
-- 37번 ⦁ 사원번호가 7902 또는 7781인 사원이름을 검색하라.
select ename from emp where empno = '7902' or empno = '7781';
-- 11번 FORD 사원과 같은 급여를 받는 사원의 사원번호를검색하라. (부질의)
select empno from emp where sal = ( select sal from emp where ename = 'ford' );
-- 13번 SCOTT 사원보다 많은 급여를 받는 사원 정보를검색하라. (부질의)
select * from emp where sal > (select sal from emp where ename = 'scott');
-- 14번 ALLEN 사원보다 적은 급여를 받는 사원 정보를검색하라. (부질의)
select * from emp where sal < (select sal from emp where ename = 'allen');
-- 15번 전체 사원의 평균 급여보다 급여가 많은 사원 정보를 검색하라. (부질의)
select * from emp where sal > (select avg(sal) from emp );
-- 16번 CHICAGO 지역에 위치하는 부서에 근무하는사원 정보를 검색하라. (부질의)
select * from emp where deptno = (select deptno from dept where loc = 'chicago');
-- 1. 상급자사원번호가 7698 또는 7839인 사원의 사원번호와 사원이름을 검색하라.
select empno, ename from emp where mgr = '7698' or mgr = '7839';
-- 2. 사원직무가 ‘MANAGER’ 또는 ‘SALESMAN’인 사원의 사원번호, 사원이름, 부서번호를 검색하라.
select empno, ename, deptno from emp where job='manager' or job='saleman';
-- 3. 사원들의 사원번호와 사원이름을 사원번호 순으로 검색하라.
select empno, ename from emp order by empno;
-- 4. 사원들의 사원번호와 사원이름을 부서번호별 이름순으로 검색하라.
select empno, ename from emp order by deptno, ename;
-- 5. 사원들의 정보를 부서별 급여가 많은 순으로 검색하라.
select * from emp order by deptno, sal desc;
-- 6. 사원들의 정보를 사원직무별 급여 순으로 검색하라.
select * from emp order by job, sal;
-- 7. 사원들의 정보를 부서번호별, 사원직무별, 급여 순으로 검색하라.
select * from emp order by depno, job, sal;
-- 8. 사원들의 사원이름을 소문자로 검색하라.
select lower(ename) from emp;
-- 9. 사원들의 사원이름, 사원직무를 소문자로 검색하라.
select lower(ename), lower(job) from emp;
-- 10. 사원들의 사원이름을 대문자로 검색하라.
select upper(ename) from emp;
-- 11. 사원들의 사원이름, 사원직무를 대문자로 검색하라.
select upper(ename), upper(job) from emp;
-- 12. 사원들의 사원이름을 첫자만 대문자로 검색하라. xx
-- 13. 사원들의 사원이름과 사원직무를 첫 자만 대문자로 검색하라. xx
-- 14. 사원들의 사원이름과 사원직무를 연결하여 검색하라.(concat이용)
select concat(ename,' ',job) from emp;
-- 15. 사원들의 사원이름과 사원이름의 첫 두글자를 검색하라.
select ename, substr(ename,1,2) from emp;
-- 16. 사원들의 사원이름, 사원직무 그리고 사원직무의 두번째부터 세글자를 검색하라.
select ename, job, substr(job,2,3) from emp;
-- 17. 사원들의 사원이름과 사원이름의 길이를 검색하라.
select ename, char_length(ename) from emp;
-- 18. 사원들의 사원이름과 사원직무의 자리수를 검색하라.
select ename, job, char_length(job) from emp;
-- 19. 사원들의 사원이름에 ‘A’가 몇번 째 위치에 있는지 검색하라.
select ename ,instr(ename,'A') from emp ;
-- 20. 사원직무에 ‘A’가 몇번 째 위치에 있는지 검색하라.
select job, instr(job, 'A') from emp;'네이버 클라우드 부트캠프 > 복습 정리' 카테고리의 다른 글
| 19일차 MySQL [ view, 스토어드 프로시저, 트리거 ] (1) | 2024.03.18 |
|---|---|
| 18일차 MySQL [ select, where, join, group order 함수 등 ] (4) | 2024.03.15 |
| 16일차 [ 데이터베이스 DB, 프로젝트 모델링 ] (0) | 2024.03.13 |
| 15일차 [ java 총 정리, 면접 ] (0) | 2024.03.12 |
| 14일차 Java [ 네트워크 입출력 ] (0) | 2024.03.11 |



