
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Array
- Uipath
- MVC
- Thymeleaf
- Scanner
- Controller
- 배열
- Eclipse
- Oracle
- rpa
- 이클립스
- html
- jsp
- db
- View
- 자료구조
- Database
- Java
- string
- JDBC
- mysql
- 상속
- API
- spring
- React
- 조건문
- Board
- SpringBoot
- jquery
- 문자열
- Today
- Total
유정잉
19일차 MySQL [ view, 스토어드 프로시저, 트리거 ] 본문
조인, 프로시저, 트리거가 제일 중요 !!!
데이터 모델링도 중요 !!! (엔티티, 속성, 관계)
[ 뷰, view : 가상테이블 ]
- 저장창치 내에서 물리적으로 존재하지 않는다. 사용자에게는 있는 것 처럼 간주된다.
- 임시작업에서 사용된다. ( 그 이후에는 사용 되지 않음 )
[ 뷰생성 ( 임시적인 사용 ) ]
CREATE VIEW v_student1 AS SELECT * FROM student WHERE stu_dept='컴퓨터정보';
DESC v_student1; -- v_student1 뷰테이블 생성 확인
SELECT * FROM v_student1; -- v_student1 뷰테이블 모든 정보 불러오기 -> 확인
create view v_emp20 as select *from emp where deptno=20;
-- 사원테이블로부터 20번 부서의 사원들로 이루어져 있는 뷰를 생성하라(v_emp20)
[ 뷰 조인 ]
create view v_enrol1 as select b.sub_name, a.sub_no, stu_no, enr_grade from enrol a, subject b
where a.sub_no=b.sub_no;
select *from v_enrol1;
create view v_emp_dept as select empno, ename, dname from dept,emp where emp.deptno=dept.deptno;
-- 사원번호, 사원이름, 부서이름을 가지는 뷰(v_emp_dept)를 생성하라
drop view v_emp_dept;
[ top n 질의 ] : 상위 n개의 데이터를 추출하는 쿼리
SELECT stu_no, stu_name, stu_height FROM (SELECT stu_no, stu_name, stu_height FROM student
WHERE stu_height is not null ORDER BY stu_height desc LIMIT 5) as sub;
-- 만약 as로 별명을 붙이지 않으면 오류 !! , null일 경우 출력하면 안 됨 !! is not null 사용하기 !!!
SELECT empno, ename, hiredate FROM (SELECT empno, ename, hiredate FROM emp
WHERE hiredate is not null ORDER BY hiredate DESC LIMIT 3) as curent;
-- 가장 최근에 입사한 3명 사원번호, 사원이름, 입사일
SELECT empno, ename, hiredate FROM emp WHERE hiredate is not null ORDER BY hiredate DESC LIMIT 3;
-- as가 없다면 구냥 이런식으로 해도 됨 !!! 위에꺼랑 똑같지만 as로 별명줄경우 안 줄경우임 ~SELECT dname
FROM (SELECT dname, avg(sal) FROM emp JOIN dept ON dept.deptno=emp.deptno
GROUP BY dname, sal ORDER BY 2 DESC LIMIT 2) as hi;
-- 부서별 평균 급여가 가장 큰 부서 2개의 부서이름 검색
[ 스토어드 프로시저(Stored Procedure) ]
- 저장 프로시저라고도 불린다. MySQL에서 제공되는 프로그래밍 기능이다.
- 쿼리문의 집합으로 어떠한 동작을 일괄 처리하기 위한 용도로 사용한다.
- 쿼리 모듈화 – 필요할 때마다 호출만 하면 훨씬 편리하게 MySQL 운영
(일종의 JAVA 함수 생각하면 됨. 블록 형태로 모듈화 되어 있는 것) , CALL 프로시저_이름( ) 한 줄로 해결되는 편리함
- 파라미터에 IN, OUT 등을 사용 가능
- 별도의 반환하는 구문이 없음 – 꼭 필요하다면 여러 개의 OUT파라미터 사용해서 값 반환 가능
- CALL로 호출
- 안에 SELECT문 사용 가능
- delimiter ; delimiter 끝낼 때 한칸 띄고 세미콜론 !!!
- 매개변수가 필요하면 ( in... out...) 필요없는 경우 그냥 괄호만 ( ) -> create procedure all_del ( )

[ 프로시저 쿼리문 예 ]
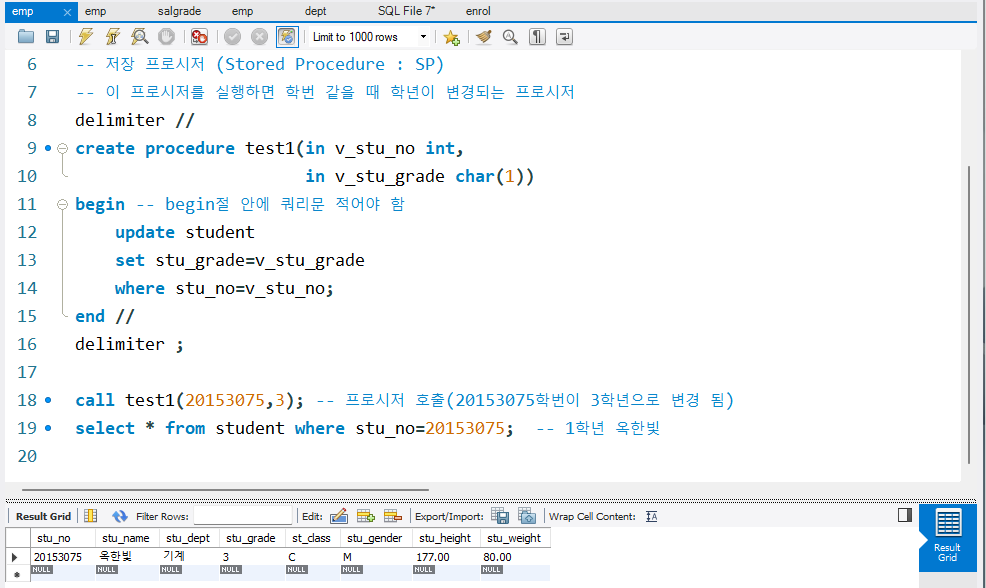
-- 저장 프로시저 (Stored Procedure : SP)
-- 이 프로시저를 실행하면 학번 같을 때 학년이 변경되는 프로시저
delimiter //
create procedure test1(in v_stu_no int,
in v_stu_grade char(1))
begin -- begin절 안에 쿼리문 적어야 함
update student
set stu_grade=v_stu_grade
where stu_no=v_stu_no;
end //
delimiter ;
call test1(20153075,3); -- 프로시저 호출(20153075학번이 3학년으로 변경 됨)
select * from student where stu_no=20153075; -- 1학년 옥한빛
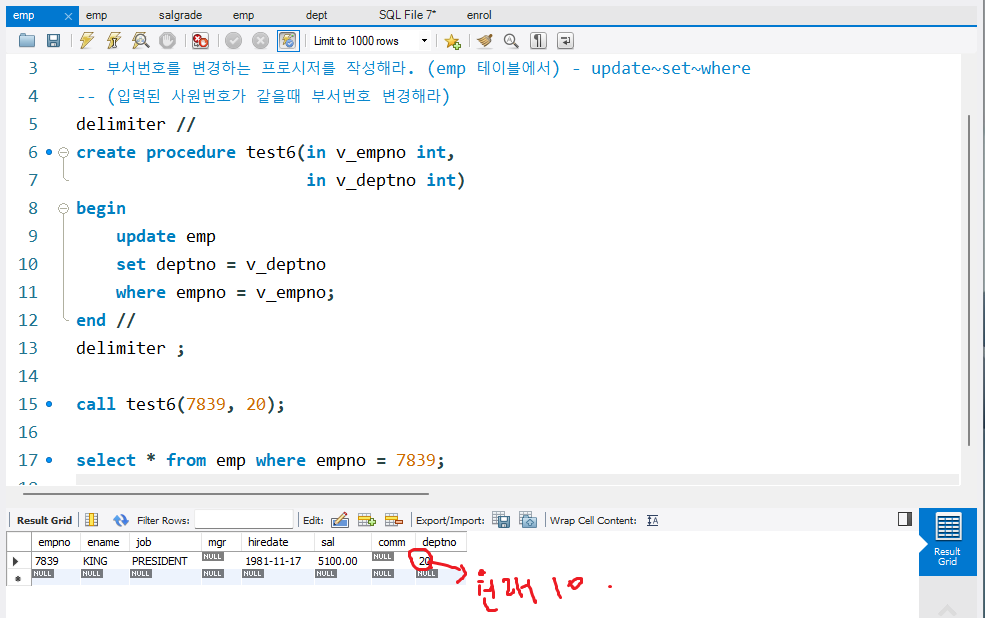
-- 부서번호를 변경하는 프로시저를 작성해라. (emp 테이블에서) - update~set~where
-- (입력된 사원번호가 같을때 부서번호 변경해라)
delimiter //
create procedure test6(in v_empno int,
in v_deptno int)
begin
update emp
set deptno = v_deptno
where empno = v_empno;
end //
delimiter ;
call test6(7839, 20);
select * from emp where empno = 7839;
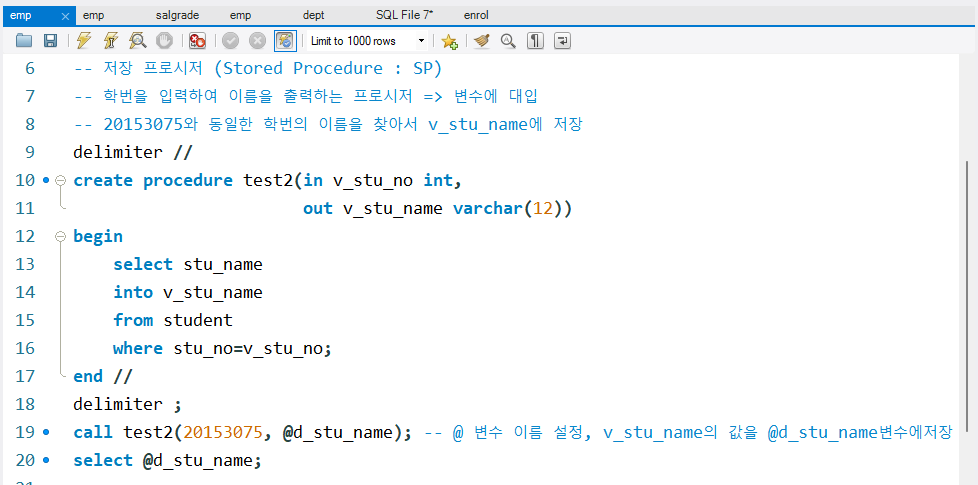
-- 저장 프로시저 (Stored Procedure : SP)
-- 학번을 입력하여 이름을 출력하는 프로시저 => 변수에 대입
-- 20153075와 동일한 학번의 이름을 찾아서 v_stu_name에 저장
delimiter //
create procedure test2(in v_stu_no int,
out v_stu_name varchar(12))
begin
select stu_name
into v_stu_name
from student
where stu_no=v_stu_no;
end //
delimiter ;
call test2(20153075, @d_stu_name); -- @ 변수 이름 설정, v_stu_name의 값을 @d_stu_name변수에저장
select @d_stu_name;
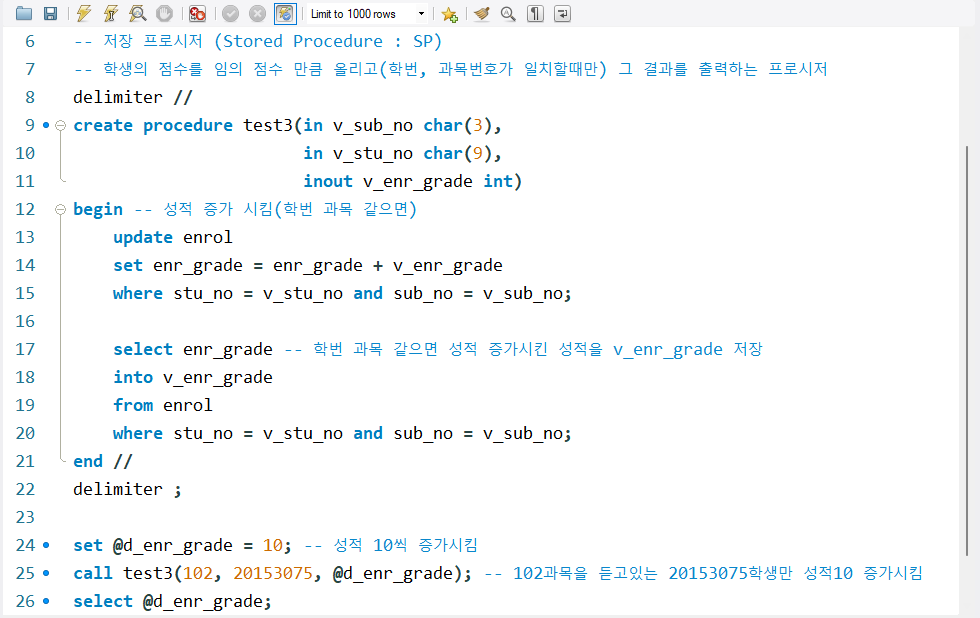
-- 저장 프로시저 (Stored Procedure : SP)
-- 학생의 점수를 임의 점수 만큼 올리고(학번, 과목번호가 일치할때만) 그 결과를 출력하는 프로시저
delimiter //
create procedure test3(in v_sub_no char(3),
in v_stu_no char(9),
inout v_enr_grade int)
begin -- 성적 증가 시킴(학번 과목 같으면)
update enrol
set enr_grade = enr_grade + v_enr_grade
where stu_no = v_stu_no and sub_no = v_sub_no;
select enr_grade -- 학번 과목 같으면 성적 증가시킨 성적을 v_enr_grade 저장
into v_enr_grade
from enrol
where stu_no = v_stu_no and sub_no = v_sub_no;
end //
delimiter ;
set @d_enr_grade = 10; -- 성적 10씩 증가시킴
call test3(102, 20153075, @d_enr_grade); -- 102과목을 듣고있는 20153075학생만 성적10 증가시킴
select @d_enr_grade;
-- 저장 프로시저 (Stored Procedure : SP)
-- 신입사원을 채용하였다. 사원번호, 사원이름, 사원직무, 상급자사원번호, 급여, 부서번호를 입력받아
-- 사원 테이블에 삽입하는 프로시저를 작성해라.11
delimiter //
create procedure test4
(in v_empno int,
in v_ename varchar(10),
in v_job varchar(9),
in v_mgr int,
in v_sal decimal(7,2),
in v_deptno int)
begin
insert into emp(empno,ename,job,mgr,sal,deptno)
values(v_empno,v_ename,v_job,v_mgr,v_sal,v_deptno);
end //
delimiter ;
call test4(7882,'히히히','대리',7902,7000,20);
select *from emp;
-- emp2 테이블에 있는 사원번호와 입력한 사원번호가 같은 사원이름과, 월급, 직무를 검색하는 프로시저 (search_pro)
delimiter //
create procedure search_pro (in v_empno int)
begin
declare v_ename varchar(10); -- 변수 선언 변수 유형을 varchar로 선택
declare v_sal decimal(7,2);
declare v_job varchar(9);
select ename, sal, job
into v_ename, v_sal, v_job
from emp
where empno = v_empno;
select v_ename, v_sal, v_job;
end //
delimiter ;
call search_pro(7369); -- (사원번호)
select * from emp;
-- emp테이블 복사해서 emp2 테이블 생성
create table emp2 as select * from emp;
select * from emp2;
-- emp2 테이블의 모든 데이터를 삭제시키는 프로시저 작성(all_del)
delimiter //
create procedure all_del ( )
begin
delete from emp2;
end //
delimiter ;
call all_del( ); -- 다 지우는 함수 불러오는 작업
select * from emp2; -- 다 지워졌는지 확인 출력
-- 삭제한 데이터를 다시 값 삽입
insert into emp2 select * from emp;
select * from emp2;
-- v_emame을 선언해서 이름에 'M'이 들어가는 사원들을 다 삭제하는 프로시저 (del_name)
delimiter //
create procedure del_name ( )
begin
delete from emp2 where ename like '%M%';
end //
delimiter ;
call del_name();
select * from emp2;
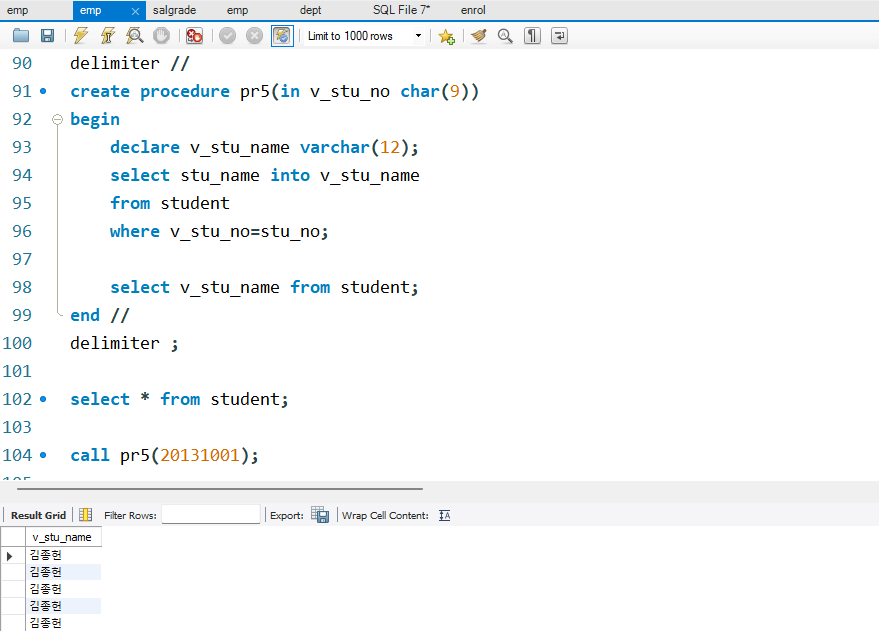
delimiter //
create procedure pr5(in v_stu_no char(9))
begin
declare v_stu_name varchar(12);
select stu_name into v_stu_name
from student
where v_stu_no=stu_no;
select v_stu_name from student;
end //
delimiter ;
select * from student;
call pr5(20131001);
[ drop procedure test2; ] => 프로시저 삭제
[ 스토어드 함수 (Stored Function) ]
set global log_bin_trust_function_creators=1; => 스토어드 함수 생성권한 사용
→ 파라미터에 IN, OUT 등을 사용할 수 없음 – 모두 입력 파라미터로 사용
→ RETURNS문으로 반환한 값의 데이터 형식 지정 – 본문 안에서는 RETURN문으로 하나의 값 반환
set global log_bin_trust_function_creators=1;
-- 스토어드 함수 생성권한 사용
delimiter //
create function test5(v_enr_grade int) -- 입력값이 있어서 (v_enr_grade int) 적음
returns char
begin
declare enr_score char; -- 변수 선언
if v_enr_grade >=90 then set enr_score:='A'; -- := 대입연산자
elseif v_enr_grade >=80 then set enr_score:='B';
elseif v_enr_grade >=70 then set enr_score:='C';
elseif v_enr_grade >=60 then set enr_score:='D';
else set enr_score:='F';
end if;
return enr_score;
end //
delimiter ;
select test5(95); -- 파라미터 입력-- 스토어드 함수 생성권한 사용
set global log_bin_trust_function_creators=1;
-- 스토어드 함수
-- 급여가 제일 높은 사원 이름을 출력하는 함수
delimiter //
create function test6() -- 입력값이 없으면 () 비워둠
returns varchar(50) -- 반환유형을 varchar로 받기
begin
declare v_ename varchar(50); -- 변수유형을 varchar로 선택
select ename into v_ename
from emp
where sal = (select max(sal) from emp);
return v_ename;
end //
delimiter ;
select distinct test6() from emp; -- 행이 여러개 출력 되기 때문에 distinct로 중복 제거
select * from emp;[ 트리거 trigger ]
※ 트리거의 개요 : 사전적 의미로 ‘방아쇠’ - 방아쇠 당기면 ‘자동’으로 총알이 나가듯 실행된다. 테이블에 DML문(Insert, Update, Delete 등) 이벤트가 발생될 때 작동한다. 테이블에 부착되는 프로그램 코드이다. 직접 실행 불가 - 테이블에 이벤트 일어나야 자동 실행된다. IN, OUT 매개 변수를 사용할 수 없다. MySQL은 View에 트리거 부착 불가 ! ! !
※ 트리거의 종류
- AFTER 트리거 : 테이블에 INSERT, UPDATE, DELETE 등의 작업이 일어났을 때 작동한다. 이름이 뜻하는 것처럼 해당 작업 후에 (After) 작동한다.
- BEFORE 트리거 : BEFORE 트리거는 이벤트가 발생하기 전에 작동한다. INSERT, UPDATE, DELETE 세 가지 이벤트로 작동한다.
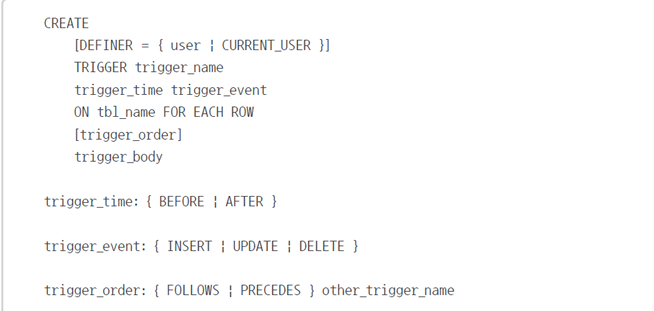
DELIMITER //
CREATE TRIGGER trigger_name
{ BEFORE | AFTER } { INSERT | UPDATE | DELETE }
ON table_name
FOR EACH ROW
BEGIN
-- 트리거 내용
END //
DELIMITER ;
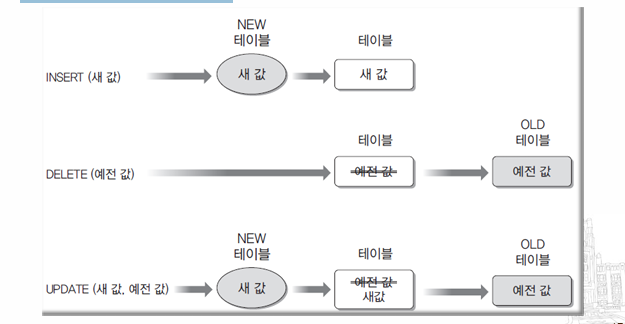
※ 트리거가 생성하는 임시 테이블 : INSERT, UPDATE, DELETE 작업이 수행되면 임시 사용 시스템 테이블 이름은 ‘NEW’와 ‘OLD’
-- 삭제한 이후의 값 넣는거는 old 즉, 예전의
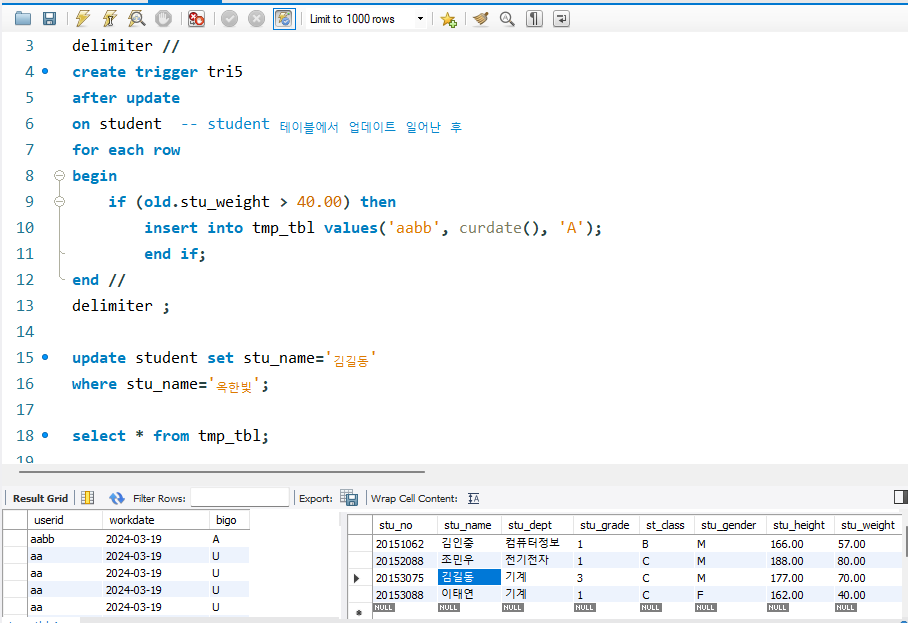
create table tmp_tbl( -- 테이블 만들고
userid varchar(10),
workdate date,
bigo char(1));
desc tmp_tbl; -- 구조 확인하고
delimiter //
create trigger tri1 -- trigger 만들기
after update
on student -- student 테이블을 update 한 이후에
for each row
begin
insert into tmp_tbl values('aa',curdate(),'U');
end //
delimiter ;
update student set stu_weight = stu_weight-10;
select distinct * from tmp_tbl;
/////// userid aa workdate 2024-03-19 bigo U 입력된 테이블 출력 ///////delimiter //
create trigger tri5
after update
on student -- student 테이블에서 업데이트 일어난 후
for each row
begin
if (old.stu_weight > 40.00) then
insert into tmp_tbl values('aabb', curdate(), 'A');
end if;
end //
delimiter ;
update student set stu_name='김길동'
where stu_name='옥한빛';
commit;
select * from tmp_tbl; -- 'aabb', curdate(), 'A' 추가된 것 확인
select * from student; -- 옥한빛이 김길동으로 이름 바뀐 것 확인

-- 사원테이블에 사원이 추가될 때 5000보다 급여가 많으면
-- emp500 테이블에 입력된 사원번호, 사원이름, 입력된날짜를 추가 입력하는 트리거 작성
create table emp500(
empno int(4),
ename varchar(10),
workdate date);
delimiter //
create trigger tri6 -- 트리거가 생성하는 임시테이블
after insert
on emp
for each row
begin
if new.sal > 5000 then
insert into emp500 values(new.empno, new.ename, now()); -- 트리거 임시테이블의 new old
end if;
end //
delimiter ;
insert into emp values(1111, 'gildong','student', 7839, now(), 5600, null, 10);
insert into emp values(2222, 'jack','student', 7839, now(), 4600, null, 10);
select * from emp500; -- jack은 sal이 4600이라 추가 되지 않음
//// empno 1111 ename gildong workdate 2021-03-19 테이블 출력 됨 ////
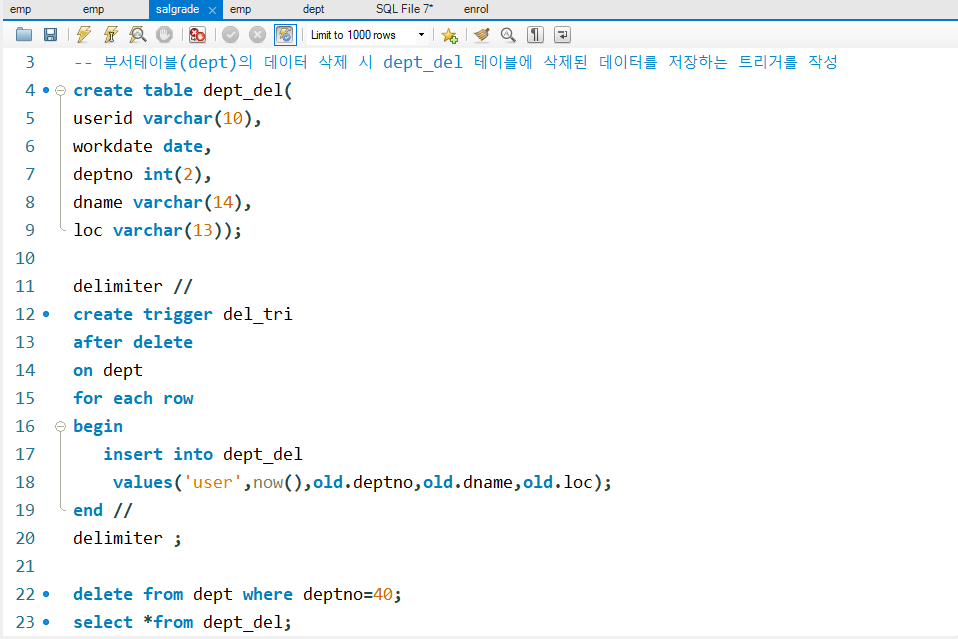
-- 부서테이블(dept)의 데이터 삭제 시 dept_del 테이블에
-- 삭제된 데이터를 저장하는 트리거를 작성
create table dept_del(
userid varchar(10),
workdate date,
deptno int(2),
dname varchar(14),
loc varchar(13));
delimiter //
create trigger del_tri
after delete
on dept
for each row
begin
insert into dept_del
values('user',now(),old.deptno,old.dname,old.loc); -- 삭제한 이후의 값 넣는거라서 old 예전의값
end //
delimiter ;
delete from dept where deptno=40;
select *from dept_del;
select *from dept;
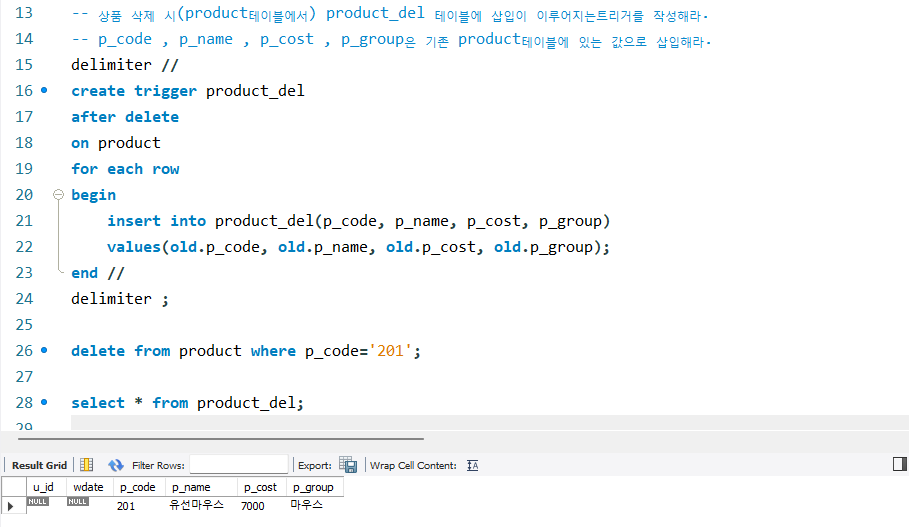
create table product_del
(u_id varchar(10),
wdate date,
p_code int(6),
p_name varchar(30),
p_cost int,
p_group varchar(30));
-- 트리거는 이벤트 처리 작업 // 프로시저는 프로그램 모듈화 호출할 때 마다 쓸 수 있다
-- 상품 삭제 시(product테이블에서) product_del 테이블에 삽입이 이루어지는트리거를 작성해라.
-- p_code , p_name , p_cost , p_group은 기존 product테이블에 있는 값으로 삽입해라.
delimiter //
create trigger product_del
after delete
on product
for each row
begin
insert into product_del(p_code, p_name, p_cost, p_group)
values(old.p_code, old.p_name, old.p_cost, old.p_group);
end //
delimiter ;
delete from product where p_code='201';
select * from product_del;
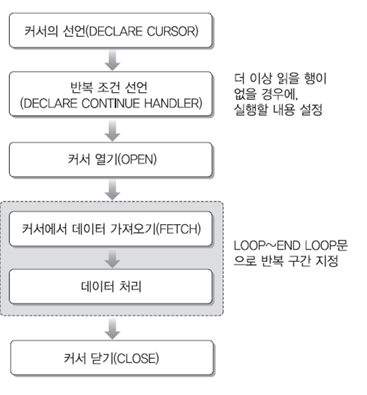
[ 커서 Cursor ] ( 별로 사용 하지 않음 )
- 스토어드 프로시저 내부에 사용
- 일반 프로그래밍 언어의 파일 처리와 방법이 비슷함 – 행의 집합을 다루기에 편리한 많은 기능을 제공
- 테이블에서 여러 개의 행을 쿼리한 후, 쿼리의 결과인 행 집합을 한 행씩 처리하기 위한 방식
-- 커서
delimiter //
create procedure test10()
begin
declare v_stu_no char(9);
declare v_sub_no char(3);
declare v_enr_grade int;
declare done int default 0;
declare endOfRow boolean default false; -- 행의 끝 여부
declare c1 cursor for select stu_no, sub_no, enr_grade
from enrol where sub_no=104; -- 커서 선언 !! 104번에 해당하는 stu_no, sub_no, enr_grade 뽑아내겠다
declare continue handler for not found set done=1; -- 반복 조건 선언 !!
-- 더 이상 읽을 행이 없으면 done 값을 1로 세팅
open c1; -- 커서 열기 !! 커서 열고 커서 이름 넣어주기
li:loop -- 반복문 이름 li로 지정
fetch from c1 into v_stu_no, v_sub_no, v_enr_grade; -- 커서에서 데이터 가져오기 !!
if done then leave li; -- fetch from select into 랑 같은 개념
end if;
select v_stu_no, v_sub_no, v_enr_grade;
end loop;
close c1; -- 커서 닫기 !!
end //
delimiter ;
call test10; -- result 결과 2개 나옴
select * from enrol;
drop procedure test10;[ MySQL 이론 ]
[ 스토어드 프로시저(Stored Procedure) ] ☆★☆★
- 저장 프로시저라고도 불린다. MySQL에서 제공되는 프로그래밍 기능이다.
- 쿼리문의 집합으로 어떠한 동작을 일괄 처리하기 위한 용도로 사용한다.
- 쿼리 모듈화 – 필요할 때마다 호출만 하면 훨씬 편리하게 MySQL 운영
(일종의 JAVA 함수 생각하면 됨. 블록 형태로 모듈화 되어 있는 것) , CALL 프로시저_이름( ) 한 줄로 해결되는 편리함
※ 스토어드 프로시저의 개요 :
- 스토어드 프로시저의 수정과 삭제
→ 수정 : ALTER PROCEDURE
→ 삭제 : DROP PROCEDURE
- 매개 변수의 사용 (입력 매개 변수를 지정하는 형식)
→ IN 입력_매개 변수_이름 데이터_형식 •입력 매개 변수가 있는 스토어드 프로시저 실행 방법
→ CALL 프로시저_이름(전달 값); •출력 매개 변수 지정 방법
→ OUT 출력_매개 변수_이름 데이터_형식 – 출력 매개 변수에 값 대입하기 위해 주로 SELECT… INTO문 사용
- 프로그래밍 기능
- 더 강력하고 유연한 기능 포함하는 스토어드 프로시저 생성
- 스토어드 프로시저 내의 오류 처리 : 스토어드 프로시저 내부에서 오류가 발생했을 경우
→ DECLARE 액션 HANDLER FOR 오류조건 처리할_문장 구문
※ 스토어드 프로시저의 특징
- MySQL의 성능 향상 : 긴 쿼리가 아니라 짧은 프로시저 내용만 클라이언트에서 서버로 전송 – 네트워크 부하 줄임
- 유지관리가 간편 : 응용 프로그램에서는 프로시저만 호출 – 데이터베이스 단에서 관련된 스토어드 프로시저의 내용 일관되게 수정/유지보수
- 모듈식 프로그래밍 가능 : 언제든지 실행 가능 + 편리한 관리 •모듈식 프로그래밍 언어와 동일핚 장점
- 보안 강화에 편리 : 스토어드 프로시저에만 접근 권핚을 주어 DB가 안전해짐
[ 스토어드 함수 (Stored Function) ]
- 사용자가 직접 만들어서 사용하는 함수
- 스토어드 프로시저와 상당히 유사 : 형태와 사용 용도에 있어 차이 있음 스토어드 함수의 개요

※ 스토어드 함수 와 스토어드 프로시저의 차이점
스토어드 함수 :
set global log_bin_trust_function_creators=1; => 스토어드 함수 생성권한 사용
→ 파라미터에 IN, OUT 등을 사용할 수 없음 – 모두 입력 파라미터로 사용
→ RETURNS문으로 반환한 값의 데이터 형식 지정 – 본문 안에서는 RETURN문으로 하나의 값 반환
→ SELECT 문장 안에서 호출
→ 안에서 집합 결과 반환하는 SELECT 사용 불가 – SELECT… INTO… 는 집합 결과 반환하는 것이
아니므로 예외적 으로 스토어드 함수에서 사용 가능
→ 어떤 계산 통해서 하나의 값 반홖하는데 주로 사용
스토어드 프로시저 : ( 스토어드 함수보단 스토어드 프로시저를 더 많이 사용 ☆ )
→ 파라미터에 IN, OUT 등을 사용 가능
→ 별도의 반환하는 구문이 없음 – 꼭 필요하다면 여러 개의 OUT파라미터 사용해서 값 반환 가능
→ CALL로 호출
→ 안에 SELECT문 사용 가능
→ 여러 SQL문이나 숫자 계산 등의 다양한 용도로 사용
[ 커서 Cursor ]
- 스토어드 프로시저 내부에 사용
- 일반 프로그래밍 언어의 파일 처리와 방법이 비슷함 – 행의 집합을 다루기에 편리한 많은 기능을 제공
- 테이블에서 여러 개의 행을 쿼리한 후, 쿼리의 결과인 행 집합을 한 행씩 처리하기 위한 방식
[ 트리거(Trigger) ] ☆★☆★
※ 트리거의 개요 : 사전적 의미로 ‘방아쇠’ - 방아쇠 당기면 ‘자동’으로 총알이 나가듯 실행된다. 테이블에 DML문(Insert, Update, Delete 등) 이벤트가 발생될 때 작동한다. 테이블에 부착되는 프로그램 코드이다. 직접 실행 불가 - 테이블에 이벤트 일어나야 자동 실행된다. IN, OUT 매개 변수를 사용할 수 없다. MySQL은 View에 트리거 부착 불가 ! ! !
※ 트리거의 종류
- AFTER 트리거 : 테이블에 INSERT, UPDATE, DELETE 등의 작업이 일어났을 때 작동한다. 이름이 뜻하는 것처럼 해당 작업 후에 (After) 작동한다.
- BEFORE 트리거 : BEFORE 트리거는 이벤트가 발생하기 전에 작동한다. INSERT, UPDATE, DELETE 세 가지 이벤트로 작동한다.
※ 트리거가 생성하는 임시 테이블 : INSERT, UPDATE, DELETE 작업이 수행되면 임시 사용 시스템 테이블 이름은 ‘NEW’와 ‘OLD’
※ BEFORE 트리거의 사용 : 테이블에 변경이 가해지기 전에 작동한다.
BEFORE 트리거의 좋은 활용 예 – BEFORE INSERT 트리거를 부착해 놓으면 입력될 데이터 값을 미리 확인해서 문제가 있을 경우에 다른 값으로 변경
생성된 트리거 확인 – SHOW TRIGGERS FROM sqlDB;
트리거를 삭제하자. – DROP TRIGGER userTbl_BeforeInsertTrg;
※다중 트리거 (Multiple Triggers) : 하나의 테이블에 동일한 트리거가 여러 개 부착되어 있는 것
Ex) AFTER INSERT 트리거가 한 개 테이블에 2개 이상 부착
※ 중첩 트리거 (Nested Triggers) : 트리거가 또 다른 트리거를 작동시키는 것. 시스템 성능 저하의 원인이 되기도 함.
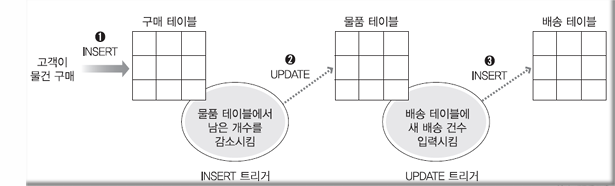
※ 트리거의 작동 순서 : 하나의 테이블에 여러 개의 트리거가 부착된 경우
트리거의 작동 순서 지정 가능 – { FOLLOWS | PRECEDES } other_trigger_name 에서 설정
중첩 트리거 작동 학습 – 테이블 내용을 전체 살펴보는 것으로 결과 확인
[ MySQL 복습 ]
[ 문제풀이 1 - book, orders, customer 테이블 생성 ]
-- 논리적 모델링 테이블 생성으로 후에 물리적 모델링 진행
create table book(
bookid int primary key,
bookname varchar(100),
publisher varchar(100),
price int);
create table orders(
orderid int primary key,
custid int,
bookid int,
saleprice int,
orderdate date);
create table customer(
custid int primary key,
name varchar(10),
address varchar(100),
phone varchar(20));
alter table orders -- book 테이블을 수정하겠다
add
constraint fk_ord foreign key(bookid)
references book(bookid);
INSERT INTO BOOK VALUES (1, '컴퓨터의 역사', '아이티', 7000);
INSERT INTO BOOK VALUES (2, '컴퓨터는 무엇일까', '굿북', 13000);
INSERT INTO BOOK VALUES (3, '컴퓨터의 이해', '비트아이티', 22000);
INSERT INTO BOOK VALUES (4, '자바 이론', '비트아이티', 35000);
INSERT INTO BOOK VALUES (5, '데이터베이스 교본', '아이티', 8000);
INSERT INTO BOOK VALUES (6, 'HTML 기술', '아이티', 6000);
INSERT INTO BOOK VALUES (7, '스프링의 개념', '에비씨미디어', 20000);
INSERT INTO BOOK VALUES (8, '스프링을 부탁해', '에비씨빛미디어', 13000);
INSERT INTO BOOK VALUES (9, '파이썬 이야기', '코딩빔', 7500);
INSERT INTO BOOK VALUES (10, 'python story', 'Pearson', 13000);
INSERT INTO CUSTOMER VALUES (1, '박건우', '인천시 송도', '010-1111-2222');
INSERT INTO CUSTOMER VALUES (2, '김선해', '서울시 종로구', '010-2111-2222');
INSERT INTO CUSTOMER VALUES (3, '장지혜', '서울시 용산구', '010-3111-2222');
INSERT INTO CUSTOMER VALUES (4, '추오섭', '경기도 의정부', '010-4111-2222');
INSERT INTO CUSTOMER VALUES (5, '박승철', '서울시 마포구', NULL);
INSERT INTO ORDERS VALUES (1, 1, 1, 6000, '2022-05-01');
INSERT INTO ORDERS VALUES (2, 1, 3, 21000, '2022-05-03');
INSERT INTO ORDERS VALUES (3, 2, 5, 8000, '2022-05-03');
INSERT INTO ORDERS VALUES (4, 3, 6, 6000, '2022-05-04');
INSERT INTO ORDERS VALUES (5, 4, 7, 20000, '2022-05-05');
INSERT INTO ORDERS VALUES (6, 1, 2, 12000, '2022-05-07');
INSERT INTO ORDERS VALUES (7, 4, 8, 13000, '2022-05-07');
INSERT INTO ORDERS VALUES (8, 3, 10, 12000, '2022-05-08');
INSERT INTO ORDERS VALUES (9, 2, 10, 7000, '2022-05-09');
INSERT INTO ORDERS VALUES (10, 3, 8, 13000, '2022-05-10');
/// 테이블 생성후 값 입력 후 잘 들어 갔는지 확인 ///
select * from book;
select * from orders;
select * from customer;
-- 1. 김선해 고객의 전화번호를 찾아라.
select phone from customer where name='김선해';
-- 2. 모든 도서의 이름과 가격을 검색해라.
select bookname, price from book;
-- 3. 모든 도서의 도서번호, 도서이름, 출판사, 가격을 검색해라.
select * from book;
-- 4. 도서 테이블에 있는 모든 출판사를 검색해라. (중복제거해서)
select distinct publisher from book;
-- 5. 가격이 20000원 미만인 도서를 검색해라.
select * from book where price < 20000;
-- 6. 가격이 10000원 이상 20000 이하인 도서를 검색해라.
select * from book where price between 10000 and 20000;
-- 7. 출판사가 ‘아이티’ 혹은 ‘비트아이티’ 인 도서를 검색해라.
select * from book where publisher='아이티' or publisher='비트아이티';
select * from book where publisher in('아이티','비트아이티');
-- 8. 출판사가 ‘아이티’ 혹은 ‘비트아이티’ 아닌 도서를 검색해라.
select * from book where not publisher='아이티' and not publisher='비트아이티';
select * from book where publisher not in('아이티','비트아이티');
-- 9. ‘컴퓨터의 역사’를 출간한 출판사를 검색해라.
select publisher from book where bookname='컴퓨터의 역사';
-- 10. 도서이름에 ‘컴퓨터’가 포함된 출판사를 검색해라.
select publisher from book where bookname like '%컴퓨터%';
-- 11. 도서이름의 왼쪽 두번 째에 ‘퓨’라는 문자열을 갖는 도서를 검색해라.
select * from book where bookname like '_퓨%';
-- 12. 컴퓨터에 관한 도서 중 가격이 20000원 이상인 도서를 검색해라.
select * from book where price >= 20000;
-- 13. 도서를 이름순으로 검색해라.
select * from book order by bookname;
-- 14. 도서를 가격순으로 검색하고, 가격이 같으면 이름순으로 검색해라.
select * from book ORDER BY price, bookname;
-- 15. 도서를 가격의 내림차순으로 검색해라. 가격이 같다면 출판사의 오름차순으로 검색해라.
select * from book ORDER BY price desc, publisher;
-- 16. 고객이 주문한 도서의 총 판매액을 구해라.
select sum(saleprice) as sum_price from orders;
-- 17. 2번 김선해 고객이 주문한 도서의 총 판매액을 구해라.
select sum(saleprice) as sum_price from orders where custid = 2; -- 만약 김선해로 찾을 시 JOIN 필요
-- 18. 고객이 주문한 도서의 총 판매액, 평균값, 최저가, 최고가를 구해라.
select sum(saleprice) as sum_price, avg(saleprice) as avg_price,
min(saleprice) as min_price, max(saleprice) as max_price from orders;
-- 19. 23서점의 도서 판매 건수를 구해라.
select count(*) as all_sale_count from orders;
-- 20. 고객별로 주문한 도서의 총 수량과 총 판매액을 구해라.
select custid, count(*), sum(saleprice) from orders group by custid;
-- 21. 가격이 8000원 이상인 도서를 구매한 고객에 대하여 고객별 주문 도서의 총 수량을 구해라. 단, 두 권 이상 구매한 고객만 구해라.
select custid, count(*) from orders where saleprice >= 8000
group by custid having count(custid)>=2;
select custid, count(*) as BUY
from (select ord.custid, ord.bookid, ord.saleprice, bk.bookname, bk.price, cust.name
from orders ord, book bk, customer cust
where ord.bookid = bk.bookid
and ord.custid = cust.custid
and bk.price >= 8000 ) AA -- AA는 별칭 안 주면 Error Code 1248 뜸.
group by custid having count(custid)>=2; -- 테이블 3개를 조인시켜서 다 연결해줌. 위와 달리 custid 2도 출력됨
-- 22. 고객과 고객의 주문에 관한 데이터를 모두 보여라.
select * from customer cust
JOIN orders ord
ON cust.custid=ord.custid;
-- 23. 고객과 고객의 주문에 관한 데이터를 고객번호 순으로 정렬하여 보여라.
select * from customer cust
JOIN orders ord
ON cust.custid=ord.custid
ORDER BY cust.custid;
-- 24. 고객의 이름과 고객이 주문한 도서의 판매가격을 검색해라.
select name, saleprice
from customer cust
JOIN orders ord ON cust.custid = ord.custid;
-- 25. 고객별로 주문한 모든 도서의 총 판매액을 구하고, 고객별로 정렬해라.
select custid, sum(saleprice) from orders group by custid order by custid;
-- 26. 고객의 이름과 고객이 주문한 도서의 이름을 구해라.
select name, bookname
from customer cust
JOIN orders ord
ON cust.custid = ord.custid
JOIN book bk
ON ord.bookid = bk.bookid;
-- 27. 가격이 20000원인 도서를 주문한 고객의 이름과 도서의 이름을 구해라.
select name, bookname
from customer cust
JOIN orders ord
ON cust.custid = ord.custid
JOIN book bk
ON ord.bookid = bk.bookid
where saleprice = 20000;
-- 28. 도서를 구매하지 않은 고객을 포함하여 고객의 이름과 고객이 주문한 도서의 판매가격을 구해라. outer join 활용
select name, bookname, price
from customer cust
LEFT JOIN orders ord
ON cust.custid = ord.custid
LEFT JOIN book bk
ON ord.bookid = bk.bookid;
-- 29. 가장 비싼 도서의 이름을 구해라.
select bookname from book ORDER BY price DESC LIMIT 1;
-- 30. 도서를 구매한 적이 있는 고객의 이름을 검색해라.
SELECT DISTINCT customer.name
FROM orders
JOIN customer ON customer.custid = orders.custid;
-- 31. 비트아이티에서 출판한 도서를 구매한 고객의 이름을 보여라.
select name
from orders join book using(bookid) join customer using(custid)
where publisher='비트아이티';
-- 32. 출판사별로 출판사의 평균 도서 가격보다 비싼 도서를 구해라.
select bk.bookname, bk.price, bk_avg.publisher, bk_avg.avg_price
from book bk,
(select publisher, avg(price) as avg_price
from book
group by publisher) bk_avg
where bk.publisher= bk_avg.publisher
and bk.price > bk_avg.avg_price;
-- 33. Book테이블에 새로운 도서 ‘공학 도서’를 삽입해라.
-- 공학 도서는 더샘에서 출간했으며 가격을 40000원이다.
insert into book values(11,'공학 도서','더샘',40000);
-- 34. Book테이블에 새로운 도서 ‘공학 도서’를 삽입해라.
-- 공학 도서는 더샘에서 출간했으며 가격은 미정이다.
insert into book values(12,'공학 도서','더샘',null);
-- 35. Customer테이블에서 고객번호가 5인 고객의 주소를
-- ‘서울시 서초구’로 변경해라.
update customer
set address='서울시 서초구'
where custid=5;
-- 36. Customer테이블에서 박승철 고객의 주소를 김선해 고객의 주소로 변경해라.
update customer
set address=(select address from (select address customer
where name='김선해') as A)
where name='박승철';
-- 37. 아이티에서 출판한 도서의 제목과 제목의 글자수를 확인해라.
select bookname, char_length(bookname)
from book
where publisher='아이티';
-- 38. 23서점의 고객 중에서 같은 성(이름 성)을 가진 사람이
-- 몇 명이나 되는지 성별 인원수를 구해라.
select sung,count(*)
from (select substr(name,1,1) as sung
from customer) A
group by sung;
-- 39. 23서점은 주문일로부터 10일 후 매출을 확정한다.
-- 각 주문의 확정일자를 구해라.
select orderdate, (orderdate+10) as confirmdate
from orders;
-- 40. 23서점이 2022년 5월 7일에 주문받은 도서의
-- 주문번호, 주문일, 고객번호, 도서번호를 모두 보여라.
-- 주문일은 ‘yyyy-mm-dd요일’형태로 표시한다.
select orderid, date_format(orderdate,'%y-%m-%d-%w요일'), custid, bookid
from orders
where orderdate='2022-05-07';
-- 41. 이름, 전화번호가 포함된 고객목록을 보여라.
-- 단, 전화번호가 없는 고객은 ‘연락처없음’으로 표시해라.
select name, ifnull(phone,'연락처없음')
from customer;
-- 42. 평균 주문금액 이하의 주문에 대해 주문번호와 금액을 보여라.
select orderid, saleprice
from orders
where saleprice <= (select avg(saleprice) from orders);
-- 43. 각 고객의 평균 주문금액보다 큰 금액의 주문 내역에 대해
-- 주문번호, 고객번호, 금액을 보여라.
select orderid, custid, saleprice
from orders
where saleprice > all(select avg(saleprice) from orders
group by custid);
SELECT o.orderid, o.custid, o.saleprice
FROM orders o
WHERE o.saleprice > (SELECT AVG(saleprice) FROM orders WHERE custid = o.custid);
-- 내가 조회하는 orders테이블의 고객아이디랑 AVG를해서 구해온데이터의 고객아이디랑 같은애들끼리의 평균치를 구하는 것 !!!
-- 각각의 고객의 자기자신의 평균금액보다 큰데이터가 필요해
-- 44. 서울시에 거주하는 고객에게 판매한 도서의 총판매액을 구해라.
select sum(saleprice)
from orders
where custid in (select custid from customer
where address like '서울%');
-----------------------------------------------------
select sum(saleprice)
from orders ord, customer cust
where ord.custid=cust.custid and address like '서울%';
-- 45. Customer테이블에서 고객번호가 5인 고객을 삭제해라.
delete from customer where custid=5;
[ 문제풀이 2 - product , trade, customer, stock 테이블 생성 ]
create table product(
p_code char(3) not null,
p_name varchar(30),
p_cost int,
p_group varchar(30),
constraint product_pk primary key(p_code));
insert into product values('101','19인치 모니터',150000,'모니터');
insert into product values('102','22인치 모니터',200000,'모니터');
insert into product values('103','25인치',260000,'모니터');
insert into product values('201','유선마우스',7000,'마우스');
insert into product values('202','무선마우스',18000,'마우스');
insert into product values('301','유선키보드',8000,'키보드');
insert into product values('302','무선키보드',22000,'키보드');
insert into product values('401','2채널 스피커',10000,'스피커');
insert into product values('402','5.1채널 스피커',120000,'스피커');
create table trade(
t_seq int not null,
p_code char(3),
c_code varchar(4),
t_date date,
t_qty int,
t_cost int,
t_tax int,
constraint trade_pk primary key(t_seq));
insert into trade
values (61,'131','101','2016-04-01',10,150000,150000);
insert into trade
values (5,'102','102','2016-04-26',8,200000,160000);
insert into trade
values (8,'103','101','2016-05-20',2,260000,52000);
insert into trade
values (3,'201','103','2016-04-13',7,7000,4900);
insert into trade
values (2,'201','101','2016-04-12',5,7000,3500);
insert into trade
values (9,'202','104','2016-06-02',8,18000,14400);
insert into trade
values (6,'301','103','2016-05-02',12,8000,9600);
insert into trade
values (10,'302','103','2016-06-09',9,22000,19800);
insert into trade
values (4,'401','104','2016-04-20',15,10000,15000);
create table customer(
c_code varchar(4) not null,
c_name varchar(30),
c_ceo varchar(12),
c_addr varchar(100),
c_phone varchar(13),
constraint custromer_pk primary key(c_code));
insert into customer values('101','늘푸른회사','김수종','경기도 안산시','010-1234-5678');
insert into customer values('102','사랑과바다','박나리','경기도 평택시','010-1122-3344');
insert into customer values('103','대한회사','이민수','서울시 구로구','010-3785-8809');
insert into customer values('104','하얀기판','허진수','경상북도 포항시','010-8569-3468');
insert into customer values('105','한마음한뜻','하민우','인천시 남동구','010-9455-6033');
select * from product;
select * from stock;
select * from trade;
select * from customer;-- 1. 상품 정보(product)테이블에 열 이름이 ‘비고’ 라는 열을 varchar2(20)으로 삽입해라.
alter table product add 비고 varchar(20);
-- 2. 1번에서 삽입한 열이 상품 정보(product)테이블에 삽입되었는지 확인해라.
select * from product;
-- 3. 상품 정보(product)테이블에 ‘비고’ 열의 구조를 char(3)으로 변경해라.
alter table product modify 비고 char(3);
-- 4. 상품코드 401에 대한 거래내역 뷰(v_trade)를 만들어라.
create view v_trade as select t.* from trade t where t.p_code = '401';
select * from v_trade;
-- 5. 상품 정보(product)테이블에 가장 최근에 들어온 거래처 코드 정보를 검색해라(top-n질의)
SELECT p.p_code, p.p_name, t.c_code, MAX(t.t_date)
FROM product p
JOIN trade t ON p.p_code = t.p_code
GROUP BY p.p_code, p.p_name, t.c_code
ORDER BY MAX(t.t_date) DESC
LIMIT 1;
select c_code from product p
join trade t
on p.p_code=t.p_code
order by t_date desc
limit 1;
-- 6. 상품을 삽입하는 프로시저를 생성해라.call p_pro(‘403’, ’7.1채널 스피커’, 180000, ‘스피커’); 완료되었다.
DELIMITER //
CREATE PROCEDURE p_pro(in v_p_code int,
in v_p_name varchar(30),
in v_p_cost int,
in v_p_group varchar(30))
BEGIN
INSERT INTO product(p_code, p_name, p_cost, p_group)
VALUES(v_p_code, v_p_name, v_p_cost, v_p_group);
END //
DELIMITER ;
CALL p_pro(403, '7.1채널 스피커', 180000, '스피커');'네이버 클라우드 부트캠프 > 복습 정리' 카테고리의 다른 글
| 22일차 MySQL [ DB 총정리, 면접 준비, 변수선언 set @, IF문, while문 ] (0) | 2024.03.21 |
|---|---|
| 21일차 Java [ 데이터베이스 입출력, DB MySQL과 eclipse 연결 ] (0) | 2024.03.20 |
| 18일차 MySQL [ select, where, join, group order 함수 등 ] (4) | 2024.03.15 |
| 17일차 MySQL [ 이론 ] ( select..from, join ) (3) | 2024.03.14 |
| 16일차 [ 데이터베이스 DB, 프로젝트 모델링 ] (0) | 2024.03.13 |



